PointNetVLAD: Deep Point Cloud Based Retrieval for Large-Scale Place Recognition(CVPR2018)
本文主要是使用纯激光的信息去做场景的检索,问题有别于回环检测但是方法的思想有相似之处可以借鉴,并且文章结合了pointnet。
三维场景的检索可以理解为已经拥有了某一区域的三维点云信息,当物体在其他任何时间、任何季节经过某一场景的时候能够识别出来,也就是”where am I in a given reference map”。

简单回顾
-
对于视觉来说,由一序列的图像可以通过SFM(Structure From Motion)来建立三维场景,得到三维地图再解决场景识别的问题,比如利用BOW(bag of words)聚合局部图像描述子(descriptor)为SFM中使用的每张图像计算出全局描述子。在reference map阶段,描述子被保存起来,检索时通过比较当前时刻全局描述子与reference map里场景的差异性,确定当前时刻对应的位置。对于基于图像的场景识别,近几年的方法较多,
如《Large-scale location recognition and the geometric burstiness problem》(CVPR2016)、《Hyperpoints and fine vocabularies for large scale location recognition》(ICCV2015)、《Are large-scale 3d models really necessary for accurate visual localization? 》(CVPR2017)、《 Camera pose voting for large-scale image-based localization》(ICCV2015)、《Appearance-Based Place Recognition and Mapping using a Learned Visual Vocabulary Model》、《Bags of binary words for fast place recognition in image sequences》、《24/7 place recognition by view synthesis》(CVPR2015)等等。
之所以基于图像的方法有较大的发展,是因为图像的信息相比于点云更丰富,特征描述子的种类也较多,并且图像像素之间的关联性更强,使得更易在这上面做文章。
-
对于点云来说,它的无序性和旋转不变性都加大了研究这些问题的难度,对于点云的传统几何的特征有限,大多数都为normal、curvature、intensity相关的特征。2017年的CVPR中有文章提出了POINTNET方法,利用深度学习去直接学习三维的点云特征,后续有较多基于pointnet的工作,这两年通过深度学习去做点云的各种问题的工作渐渐多起来。
文章方法介绍
先做问题的一些假设和定义,假设现在已有某区域的reference map $\mathcal{M}$,其中的三维点云是相对于一个固定的全局坐标系而建立。接着通过某一种切割的方式将这个$\mathcal{M}$切成$M$块使得每一块场景覆盖的区域基本相同,然后通过降采样将每个场景的点云的数量变为相同的。


对于query场景$q$来说,它有N个点,将这N个点输入到下面的框架中得到该场景的全局描述子:
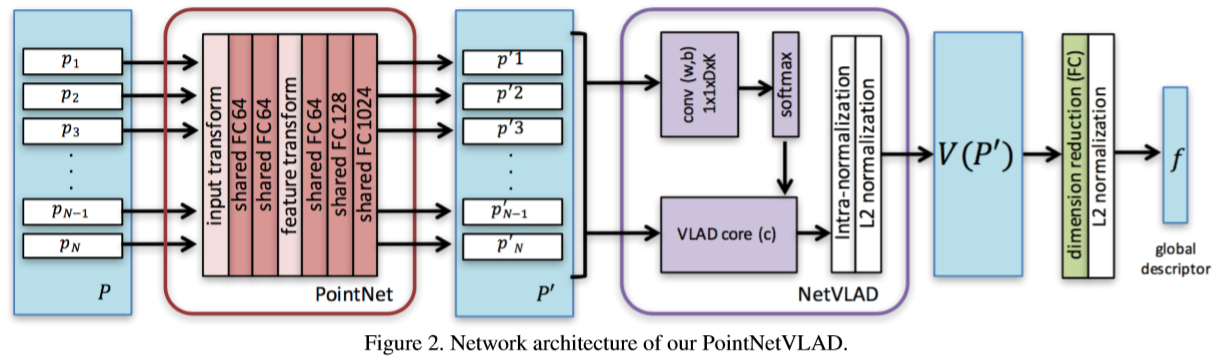
该框架主要由两个部分组成,Pointnet和NetVLAD。接下来分别讲解一下这两个部分,首先我们有一片输入的点云$P={p_1,…,p_N}$,经过pointnet的学习框架得到高维的逐点特征,假设有$D»3$维,则每个点对应一个$1\times D$的向量,则得到$P’ = {p’_1,…,p’_N}$,接下来进入NetVLAD部分,因为pointnet的缺陷是不能很好得到点云局部的信息,所以作者采用的聚类的方式,NetVLAD将$P’$作为输入分别走两条线最后合成VLAD core,首先通过聚类得到$K$个聚类中心${c_1,…,c_K | c_k\in \mathbb{R}^D}$(ps:从代码中发现,这里的$K$是固定的,也就是说提前就设定好了$K$的值,个人觉得这样的处理方式不妥,因为不是每个submap都适合分成相同数量的聚类集合),然后对于每一个$p’_i$,其与聚类中心$k$联系是否紧密,通过softmax得到一个$[0,1]$之间的概率 最后再把$P’$和系数$a$以及聚类中心组合起来形成VLAD core 输出$(D\times K)$维特征向量$V(P’) = [V_1(P’),…,V_k(P’)]$。最后通适当降维(这里降维是因为直接输出的特征向量维数太高,会影响计算时间并且会包含冗余信息)和$L_2$normalization后得到该场景的全局描述符。
接下来介绍如何进行learning,文章提出了一种”Lazy Triplet”的三元组训练方式,对于某一区域,切割出了$M$块场景,对于某一场景设为anchor point cloud,这些$M-1$块中存在一个场景跟它是structural similar,记为$P_{pos}$,还有一些不相似的,组成了集合${P_{neg}}$,最终形成三元组$\mathcal{T} = {P_a, P_{pos},{P_{neg}}}$。训练的目标是为了让相似的距离更近,不相似的距离更远 其中$[…]_+$ 是hinge loss,$\alpha$是一个平衡边界的常数。
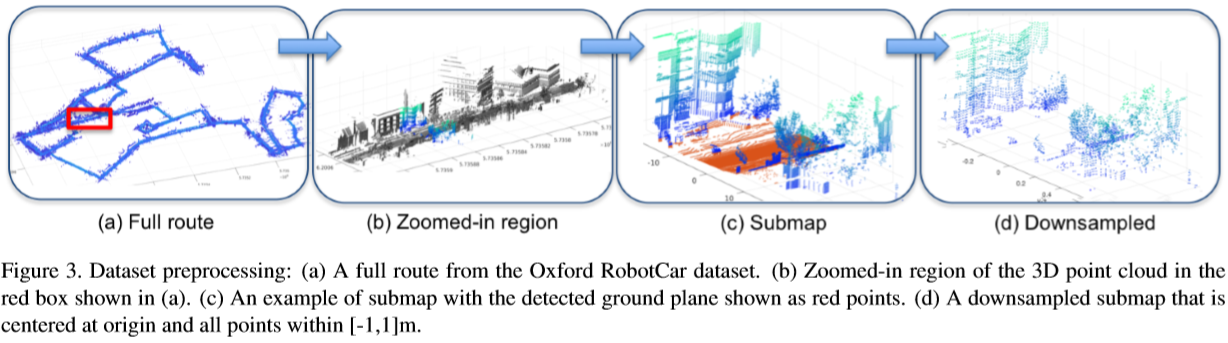
最后再贴一张图形象解释这个切割reference map的过程
代码理解
本文的代码可以主要从三个部分去阅读,分别是数据集的预处理、文章方法框架的编写和训练部分的代码。
-
数据的预处理。
数据的预处理代码分成两块来写,首先用matlab把原始点云数据切成相隔20m的块,再用python形成三元组。
-
matlab部分:文件名:generate_submaps.m
首先读取各种参数,如文件路径,各传感器之间的外参和时间戳文件,这里主要讲解如何切割成块。
%%%%%%%%%%%%%%%%%%%%%%%%%GET SCANS TO GENERATE SUBMAP%%%%%%%%%%%%%%%%%%%%% while(getDistance(laser_global_poses{i}(1,4), laser_global_poses{i}(2,4),laser_global_poses{frame_start}(1,4), laser_global_poses{frame_start}(2,4))<submap_cover_distance) if(j>(length(l_timestamps)-1)) break end j=j+1; while((getDistance(laser_global_poses{i}(1,4), laser_global_poses{i}(2,4), laser_global_poses{j}(1,4), laser_global_poses{j}(2,4))<laser_reading_distance)... && (getRotation(laser_global_poses{i}(1:3,1:3), laser_global_poses{j}(1:3,1:3))*180/pi <laser_reading_angle)) j=j+1; if(j>(length(l_timestamps)-1)) break end end frames=[frames j]; if(j>(length(l_timestamps)-1)) break end if(getDistance(laser_global_poses{frame_start}(1,4), laser_global_poses{frame_start}(2,4), laser_global_poses{j}(1,4), laser_global_poses{j}(2,4))>dist_start_next_frame && got_next==0) start_next_frame=frames(1,end); got_next=1; end i=j; end这里通过计算第i帧和start帧之间的距离来判断是否到达20m临界值,中间的while循环表示找到汽车急转弯的情况,因为汽车急转弯的时候对点云的形成影响较大,并且也是一个特殊的时间点,需要在frames中加入这个位置的index,最后代表寻找下一个submap的start帧。
%%%%%%%Build Pointcloud%%%%%%% pointcloud = []; for i=frames scan_path = [laser_dir num2str(l_timestamps(i,1)) '.bin']; scan_file = fopen(scan_path); scan = fread(scan_file, 'double'); fclose(scan_file); scan = reshape(scan, [3 numel(scan)/3]); scan(3,:) = zeros(1, size(scan,2)); % 将当前scan的points相对于激光雷达坐标系转到framestart的坐标系中 scan = inv(laser_global_poses{frame_start})*laser_global_poses{i} * G_ins_laser * [scan; ones(1, size(scan,2))]; pointcloud = [pointcloud scan(1:3,:)]; end这里主要说明最后一个对scan的赋值操作,这里表示将这一帧的点云从当前激光雷达坐标系转换到start frame坐标系中。
%make spread s=0.5/d sum=0; for i=1:size(output,2) sum=sum+sqrt((output(1,i)-x_cen)^2+(output(2,i)-y_cen)^2+(output(3,i)-z_cen)^2); end d=sum/size(output,2); s=0.5/d; T=[[s,0,0,-s*(x_cen)];... [0,s,0,-s*(y_cen)];... [0,0,s,-s*(z_cen)];... [0,0,0,1]]; scaled_output=T*[output; ones(1, size(output,2))]; scaled_output=-scaled_output; %Enforce to be in [-1,1] and have exactly target_pc_size points cleaned=[]; for i=1:size(scaled_output,2) if(scaled_output(1,i)>=-1 && scaled_output(1,i)<=1 && scaled_output(2,i)>=-1 && scaled_output(2,i)<=1 ... && scaled_output(3,i)>=-1 && scaled_output(3,i)<=1) cleaned=[cleaned,scaled_output(:,i)]; end end中间有一部分注释说的很清楚,不需要解释,最后在这里说明作者是如何切割的,通过将之前逐帧拼凑起来的点云scale到$[-1,1]^3$之间,然后剃掉范围之外的点,点数不够的话通过permutation进行补充。最终就切割成了块状点云。
-
python部分,形成三元组query。文件名:generate_train_tuples_baseline.py
runs_folder= "oxford/" filename = "pointcloud_locations_20m_10overlap.csv" ## In file, cordinate presents centroid of each submap pointcloud_fols="/pointcloud_20m_10overlap/" ## folder that contains .bin files首先解释一下,开始部分的filename、pointcloud_fols变量代表的意思,filename对应是个.cvs文件,是表述每个submap对应的时间戳和点云中心的坐标,这里的坐标用的东北天坐标系,并且角度是俯视,所以只有northing和easting两列;pointcloud_fols是一个文件夹,里面包含每个时间戳对应submap的.bin文件。
####Initialize pandas DataFrame df_train= pd.DataFrame(columns=['file','northing','easting']) df_test= pd.DataFrame(columns=['file','northing','easting']) ## for each folder, for folder in folders: df_locations= pd.read_csv(os.path.join(base_path,runs_folder,folder,filename),sep=',') df_locations['timestamp']=runs_folder+folder+pointcloud_fols+df_locations['timestamp'].astype(str)+'.bin' df_locations=df_locations.rename(columns={'timestamp':'file'}) for index, row in df_locations.iterrows(): if(check_in_test_set(row['northing'], row['easting'], p, x_width, y_width)): df_test=df_test.append(row, ignore_index=True) else: df_train=df_train.append(row, ignore_index=True)tuples有train和test两个部分,首先pandas.DataFrame建立表格型数据结构,跟字典类似,有key值,由key值找到对应的存储数据,这里用DataFrame来存储当前submap的文件名和northing、easting的值,为后续KD Tree的建立做好准备。代码中,以Oxford数据的每个文件夹为基础,利用check_in_test_set函数做判断条件,将每个submap的’file’、’northing’、’easting’ 值放进train或者test的DataFrame中。
def construct_query_dict(df_centroids, filename): tree = KDTree(df_centroids[['northing','easting']]) ## construct a kdtree ind_nn = tree.query_radius(df_centroids[['northing','easting']],r=10) ## get indexes of similar sbmps, including itself ind_r = tree.query_radius(df_centroids[['northing','easting']], r=50) ## get indexes of dissimilar sbmps queries={} for i in range(len(ind_nn)): query=df_centroids.iloc[i]["file"] positives=np.setdiff1d(ind_nn[i],[i]).tolist() ## for a fixed anchor submap, get indexes of sbmps that similar with anchor sbmp, except itself and put them into positive list negatives=np.setdiff1d(df_centroids.index.values.tolist(),ind_r[i]).tolist() ## for a fixed anchor submap, get sbmps indexes that dissimilar with anchor sbmp, and put them into negative list random.shuffle(negatives) queries[i]={"query":query,"positives":positives,"negatives":negatives} ## create a dictionary about the training tuple print("queries[0]: {}".format(queries[0])) with open(filename, 'wb') as handle: pickle.dump(queries, handle, protocol=pickle.HIGHEST_PROTOCOL) print("Done ", filename)最后就是建立query了。首先根据DataFrame生成KDTree,文章里positives的submap之间是距离小于10,所以这里r=10;同样negatives的submap之间的距离要大于50,r=50。KDTree返回的是每个节点(这里是submap)距离相距小于10的所有节点的Index,anchor节点按照DataFrame里的顺序排列,接下来从第一个节点开始,用np.setdissld函数将除该节点本身外的positve节点的Index赋给positives变量,同理可对negatives做这样的操作,注意这里有个小细节和先前不同,用的补集的思想得到距离大于50的所有节点的Index。最后将按’query’、’positives’、’negatives’三个键值形式形成一个字典,用pickle库保存,形成.pickle文件。
-
-
文章方法框架
文件名:pointvlad_cls.py
文章方法框架放在了forward函数中,输入为$batch \times num_pointsets_per_query \times point_num_per_pointset \times 3$,输出为$batch \times num_points_per_query \times out_dim$。
## get values of every dimension batch_num_queries = point_cloud.get_shape()[0].value num_pointclouds_per_query = point_cloud.get_shape()[1].value num_points = point_cloud.get_shape()[2].value CLUSTER_SIZE=64 ## SET cluster number in advance OUTPUT_DIM=256 ## SET output dimensions point_cloud = tf.reshape(point_cloud, [batch_num_queries*num_pointclouds_per_query, num_points,3])提取输入的数据每个维度的值,并且为了后续的易操作性,将pointcloud reshape成$batch * num_pointclouds_per_query \times num_points \times 3$,即相当于重新定义了batch。
## pointnet part , same as code of pointnets with tf.variable_scope('transform_net1') as sc: input_transform = input_transform_net(point_cloud, is_training, bn_decay, K=3) point_cloud_transformed = tf.matmul(point_cloud, input_transform) input_image = tf.expand_dims(point_cloud_transformed, -1) net = tf_util.conv2d(input_image, 64, [1,3], padding='VALID', stride=[1,1], is_training=is_training, scope='conv1', bn_decay=bn_decay) net = tf_util.conv2d(net, 64, [1,1], padding='VALID', stride=[1,1], is_training=is_training, scope='conv2', bn_decay=bn_decay) with tf.variable_scope('transform_net2') as sc: feature_transform = feature_transform_net(net, is_training, bn_decay, K=64) net_transformed = tf.matmul(tf.squeeze(net, axis=[2]), feature_transform) net_transformed = tf.expand_dims(net_transformed, [2]) net = tf_util.conv2d(net_transformed, 64, [1,1], padding='VALID', stride=[1,1], is_training=is_training, scope='conv3', bn_decay=bn_decay) net = tf_util.conv2d(net, 128, [1,1], padding='VALID', stride=[1,1], is_training=is_training, scope='conv4', bn_decay=bn_decay) net = tf_util.conv2d(net, 1024, [1,1], padding='VALID', stride=[1,1], is_training=is_training, scope='conv5', bn_decay=bn_decay)这一段是沿用的PointNet文章的code,最终得到1024维特征。得到的net是形状为$BATCH \times 1 \times 1 \times 1024$的tensor。
## output of pointnet part as input of netvlad part NetVLAD = lp.NetVLAD(feature_size=1024, max_samples=num_points, cluster_size=CLUSTER_SIZE, output_dim=OUTPUT_DIM, gating=True, add_batch_norm=True, is_training=is_training) ## reshaped in the following form: 'batch_size*max_samples' x 'feature_size' net= tf.reshape(net,[-1,1024]) ## before inputed into netvlad, feature data are normalized through axis 1 net = tf.nn.l2_normalize(net,1) output = NetVLAD.forward(net) #output = NetVLAD.forward(net) ## output dimension is batch_size * num_queries × output_dimension print(output) ## L2 normalization output = tf.nn.l2_normalize(output,1) ## restore shape output = tf.reshape(output,[batch_num_queries,num_pointclouds_per_query,OUTPUT_DIM])这一段为NetVLAD部分,初始化后,将reshape过后的特征L2正则化,输入至NetVLAD中,与文章图示不一样的是,这里输出的向量已经为降维过后的了,最后再做一次L2正则化后就得到了最终的descriptor。下面解释一下NetVLAD具体怎么做的。文件:loupe.py
cluster_weights = tf.get_variable("cluster_weights", [self.feature_size, self.cluster_size], initializer = tf.random_normal_initializer( stddev=1 / math.sqrt(self.feature_size))) activation = tf.matmul(reshaped_input, cluster_weights) if self.add_batch_norm: activation = slim.batch_norm( activation, center=True, scale=True, is_training=self.is_training, scope="cluster_bn", fused=False) else: cluster_biases = tf.get_variable("cluster_biases", [self.cluster_size], initializer = tf.random_normal_initializer( stddev=1 / math.sqrt(self.feature_size))) activation += cluster_biases这里是完成公式(2)里$w^T_kp’_i+b_k$的操作,即引入cluster的参数,用于后续反向传播得到较好的cluster模型。
activation = tf.nn.softmax(activation) ## defult axis = -1, which means along the cluster_size axis activation = tf.reshape(activation, [-1, self.max_samples, self.cluster_size])对得到的activation做softmax,即完成公式中 的操作。
a_sum = tf.reduce_sum(activation,-2,keep_dims=True) ## cluster_size has been set to 64 ## cluster_weights2 means K cluster centers with feature_size dimensions cluster_weights2 = tf.get_variable("cluster_weights2", [1,self.feature_size, self.cluster_size], initializer = tf.random_normal_initializer( stddev=1 / math.sqrt(self.feature_size))) a = tf.multiply(a_sum,cluster_weights2) activation = tf.transpose(activation,perm=[0,2,1]) reshaped_input = tf.reshape(reshaped_input,[-1, self.max_samples, self.feature_size]) vlad = tf.matmul(activation,reshaped_input) vlad = tf.transpose(vlad,perm=[0,2,1]) vlad = tf.subtract(vlad,a)接下来的操作有一点技巧性,作者并没有按照公式中的步骤来把再乘softmax result,而是把两者拆开分别求值,变成 和 。
对于第二部分$c_k$,作者建立新的参数cluster_weights2去学习它,将a_sum和cluser_weights2相乘就表达出了第二部分的式子;对于第一部分,将activation的二三维(num_point、cluster_size)换位置,再乘以原始的input $p’$,最后位置换回来就实现了第一部分式子的操作。最终两者相减。
vlad = tf.nn.l2_normalize(vlad,1) ## form a vector with shape batch_size(batch_num_queries*num_pointclouds_per_query) × cluster_size * feature_size vlad = tf.reshape(vlad,[-1, self.cluster_size*self.feature_size]) ## intra-normalization L2 normalization vlad = tf.nn.l2_normalize(vlad,1) ## dimension reduction operation(FC) hidden1_weights = tf.get_variable("hidden1_weights", [self.cluster_size*self.feature_size, self.output_dim], initializer=tf.random_normal_initializer( stddev=1 / math.sqrt(self.cluster_size))) ##Tried using dropout #vlad=tf.layers.dropout(vlad,rate=0.5,training=self.is_training) vlad = tf.matmul(vlad, hidden1_weights)这里就是进行intra-normalization和降维的操作了,这里作者用FC去做降维,写了一个隐藏层,将输出维数调为output_dim。
-
训练部分
文件名:train_pointnetvlad.py
这个文件的代码大致框架跟PointNet很相似,我在这里就简单解释一下。
with tf.variable_scope("query_triplets") as scope: vecs= tf.concat([query, positives, negatives, other_negatives],1) print(vecs) out_vecs= forward(vecs, is_training_pl, bn_decay=bn_decay) print(out_vecs) q_vec, pos_vecs, neg_vecs, other_neg_vec= tf.split(out_vecs, [1,POSITIVES_PER_QUERY,NEGATIVES_PER_QUERY,1],1)这里是framework的主要部分,先将query、poistive、negative、other_negatives按第二维拼起来,得到$batch \times num_pointsets_per_query \times point_num_per_pointset \times 3$的输入vecs,然后经过PointNetVLAD网络得到输出out_vecs,此时的输出是拼起来的,所以下一步用tf.split将输出切成query_vec,pos_vecs,neg_vecs,other_neg_vec四个部分。
for epoch in range(MAX_EPOCH): log_string('**** EPOCH %03d ****' % (epoch)) sys.stdout.flush() train_one_epoch(sess, ops, train_writer, test_writer, epoch, saver)这里用for循环开始训练,每一次经过train_one_epoch函数后参数都会更新一次。
for j in range(BATCH_NUM_QUERIES): if (len(TRAINING_QUERIES[batch_keys[j]]["positives"]) < POSITIVES_PER_QUERY): faulty_tuple = True break # no cached feature vectors if (len(TRAINING_LATENT_VECTORS) == 0): q_tuples.append( get_query_tuple(TRAINING_QUERIES[batch_keys[j]], POSITIVES_PER_QUERY, NEGATIVES_PER_QUERY, TRAINING_QUERIES, hard_neg=[], other_neg=True)) # q_tuples.append(get_rotated_tuple(TRAINING_QUERIES[batch_keys[j]],POSITIVES_PER_QUERY,NEGATIVES_PER_QUERY, TRAINING_QUERIES, hard_neg=[], other_neg=True)) # q_tuples.append(get_jittered_tuple(TRAINING_QUERIES[batch_keys[j]],POSITIVES_PER_QUERY,NEGATIVES_PER_QUERY, TRAINING_QUERIES, hard_neg=[], other_neg=True)) elif (len(HARD_NEGATIVES.keys()) == 0): query = get_feature_representation(TRAINING_QUERIES[batch_keys[j]]['query'], sess, ops) random.shuffle(TRAINING_QUERIES[batch_keys[j]]['negatives']) negatives = TRAINING_QUERIES[batch_keys[j]]['negatives'][0:sampled_neg] hard_negs = get_random_hard_negatives(query, negatives, num_to_take) print(hard_negs) q_tuples.append( get_query_tuple(TRAINING_QUERIES[batch_keys[j]], POSITIVES_PER_QUERY, NEGATIVES_PER_QUERY, TRAINING_QUERIES, hard_negs, other_neg=True)) # q_tuples.append(get_rotated_tuple(TRAINING_QUERIES[batch_keys[j]],POSITIVES_PER_QUERY,NEGATIVES_PER_QUERY, TRAINING_QUERIES, hard_negs, other_neg=True)) # q_tuples.append(get_jittered_tuple(TRAINING_QUERIES[batch_keys[j]],POSITIVES_PER_QUERY,NEGATIVES_PER_QUERY, TRAINING_QUERIES, hard_negs, other_neg=True)) else: query = get_feature_representation(TRAINING_QUERIES[batch_keys[j]]['query'], sess, ops) random.shuffle(TRAINING_QUERIES[batch_keys[j]]['negatives']) negatives = TRAINING_QUERIES[batch_keys[j]]['negatives'][0:sampled_neg] hard_negs = get_random_hard_negatives(query, negatives, num_to_take) hard_negs = list(set().union(HARD_NEGATIVES[batch_keys[j]], hard_negs)) print('hard', hard_negs) q_tuples.append( get_query_tuple(TRAINING_QUERIES[batch_keys[j]], POSITIVES_PER_QUERY, NEGATIVES_PER_QUERY, TRAINING_QUERIES, hard_negs, other_neg=True)) # q_tuples.append(get_rotated_tuple(TRAINING_QUERIES[batch_keys[j]],POSITIVES_PER_QUERY,NEGATIVES_PER_QUERY, TRAINING_QUERIES, hard_negs, other_neg=True)) # q_tuples.append(get_jittered_tuple(TRAINING_QUERIES[batch_keys[j]],POSITIVES_PER_QUERY,NEGATIVES_PER_QUERY, TRAINING_QUERIES, hard_negs, other_neg=True)) if (q_tuples[j][3].shape[0] != NUM_POINTS): no_other_neg = True break if batch_keys[j] == 0: is_extraction = True然后进入train_one_epoch函数中,这里解释一下batch形成时的细节。batch是两个anchor对应的tuple append起来的,如果是训练的epoch<=5,那么training_latent_vectors为空,所以不会引入HARD_NEGATIVES;当epoch>5时,引入HARD_NEGATIVES,每一个anchor对应的hard_neg会通过set().union合并到HARD_NAGATIVE。另外当epoch>5时,每过700个anchor,就会更新一次training_latent_vectors。