基于点云场景的三维物体检测算法及应用
主讲人:史少帅 香港中文大学PHD

目前在KITTI数据集上做3D物体检测的方法
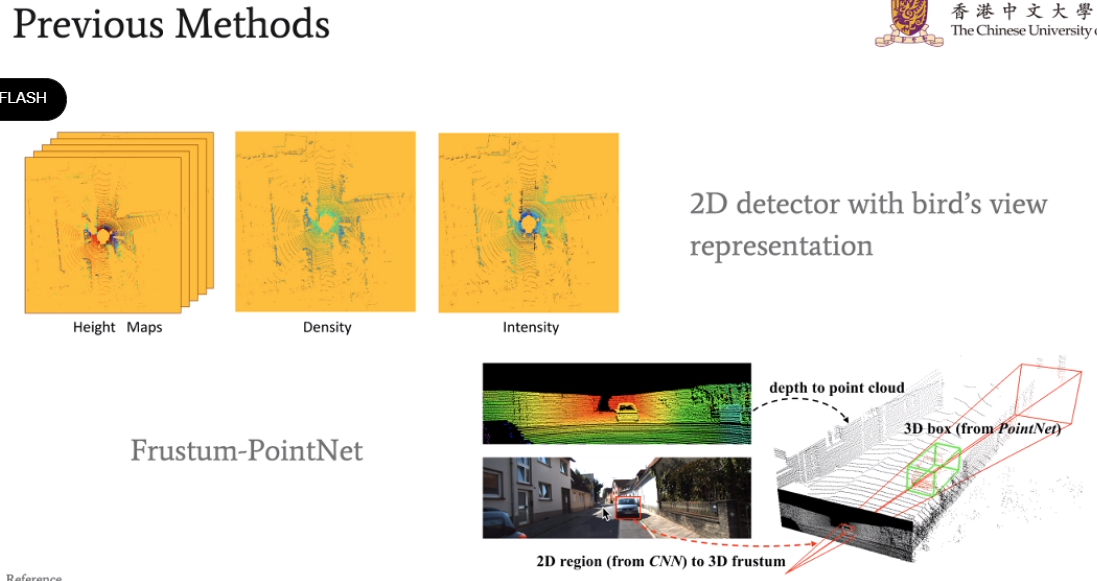
在比较早的时候做object detection的方法,主要分成两种,第一种思路是把3D点云投影到2D平面中,再从中去检测物体;第二种思路是将point-base的方法和图像进行结合,先在图像中利用某种图像方法检测到物体后再去对应切割point cloud。

讲者的第一个工作,用point-base的方法去做object detection。
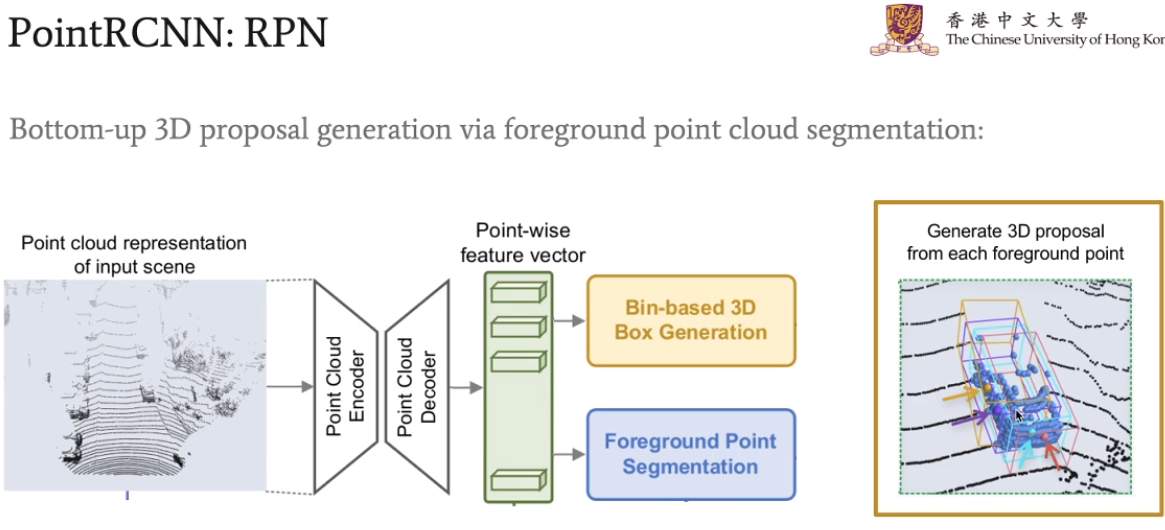
PointRCNN的主要框架,其中point cloud encoder部分是引用的pointnet++的方法。
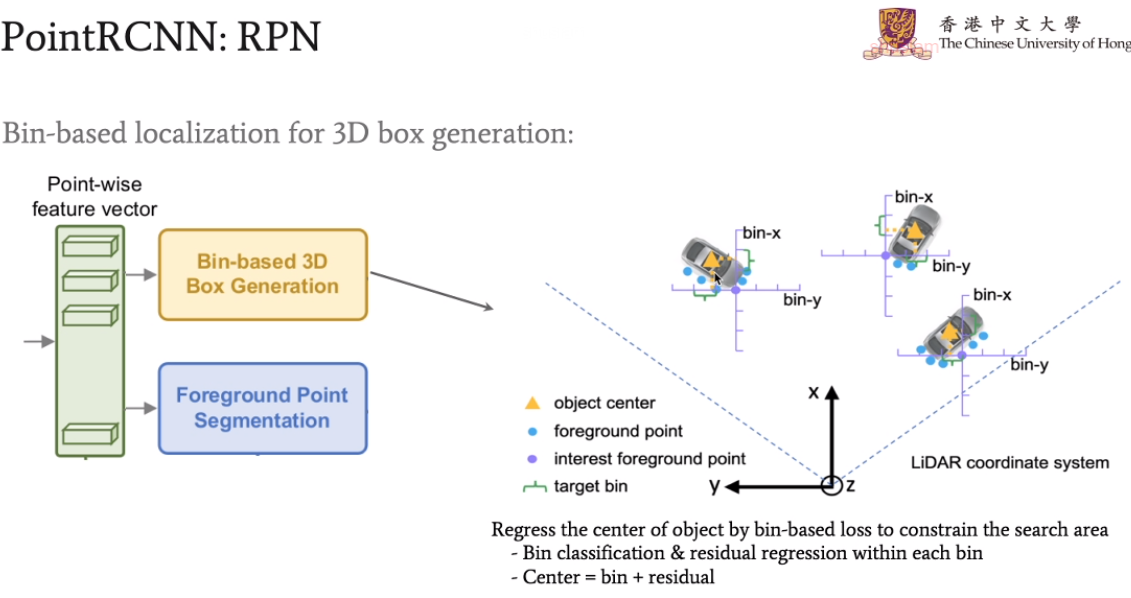
利用前景点和分割出的bin去确定object center。
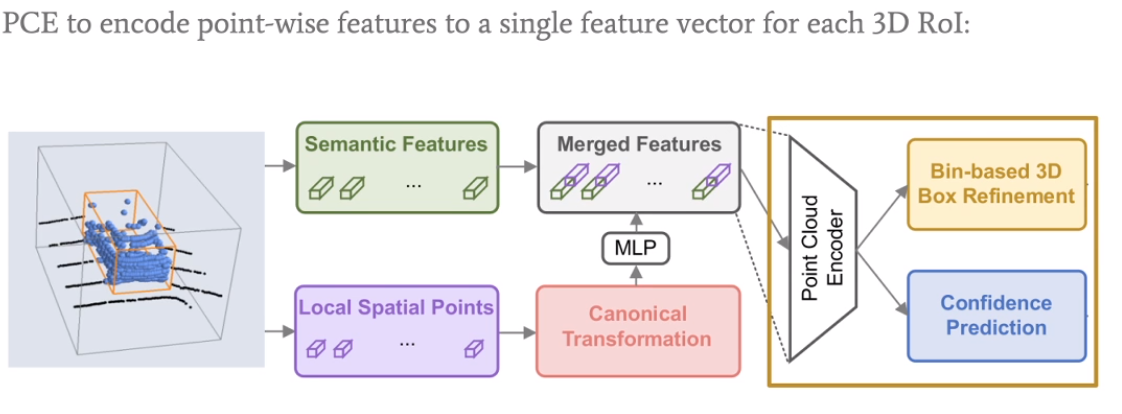
通过point-wise feature去形成一个proposal,再通过pointnet++ encoder过程去得到rcnn的confidence
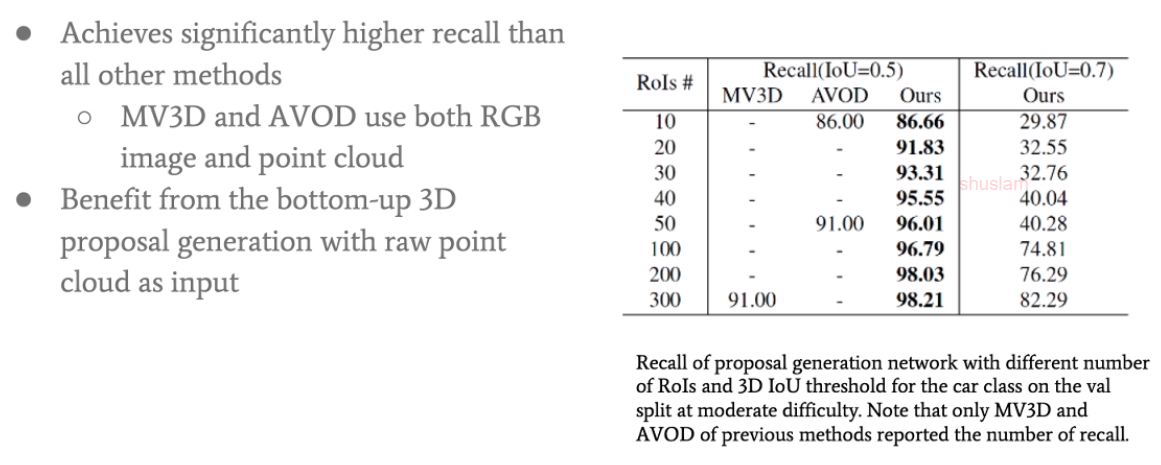
与图像的方法和投影的方法进行比较,基于raw point的方法更能得到detail的feature,效果较好。

讲者的另一篇基于voxel的方法。
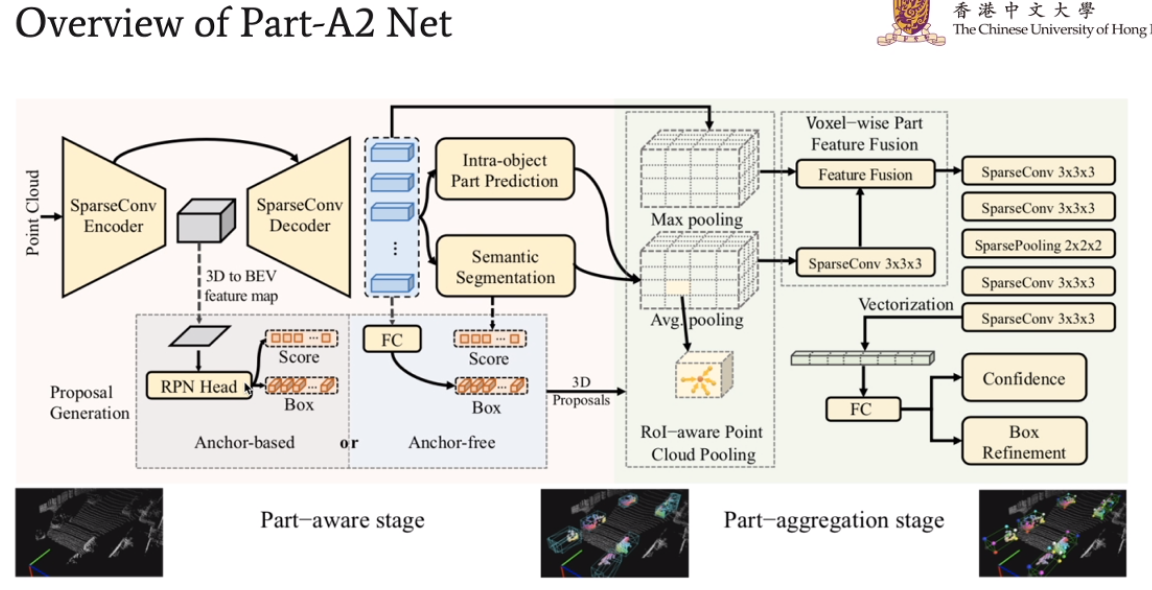
方法的整个框架概览。
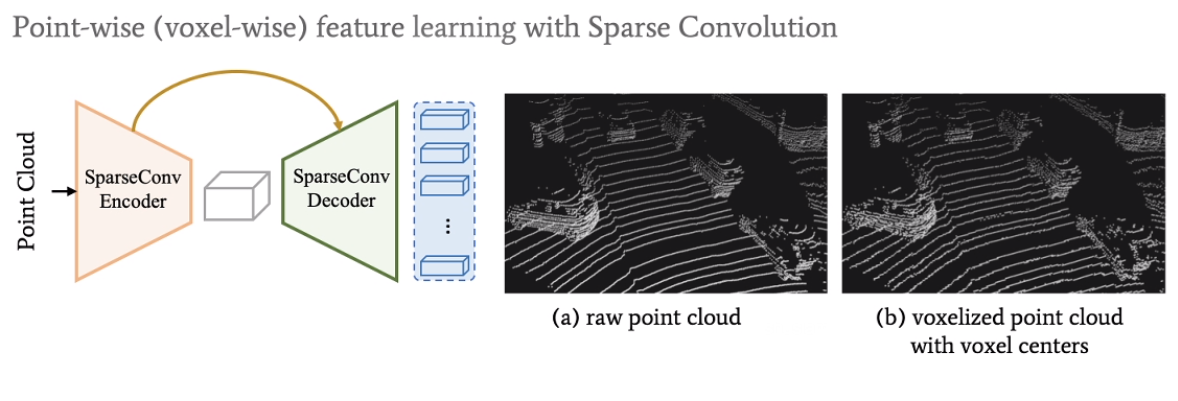
只在有点的地方进行voxelization ,对应用的sparse convolution。产生有voxel组成的点云
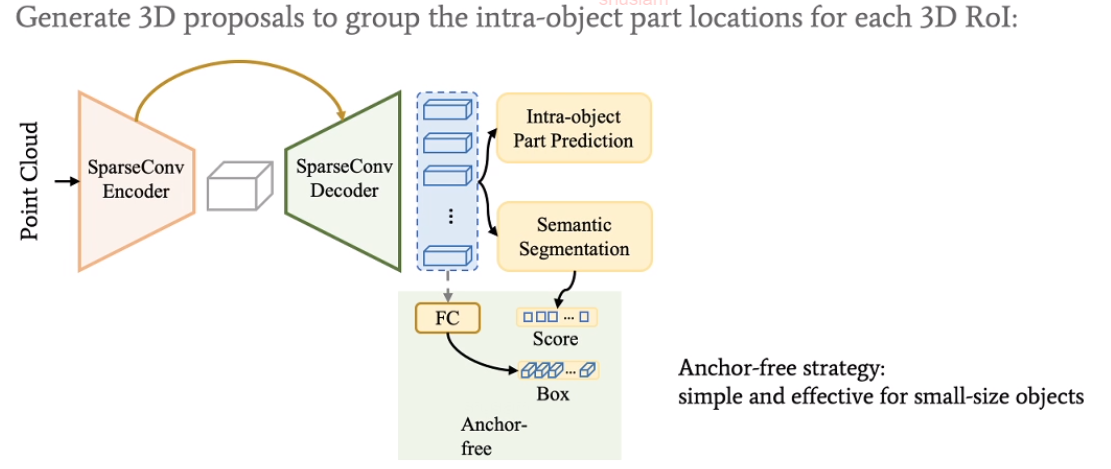
用anchor-free的策略去得到初始的bounding box。此策略对小物体更友好
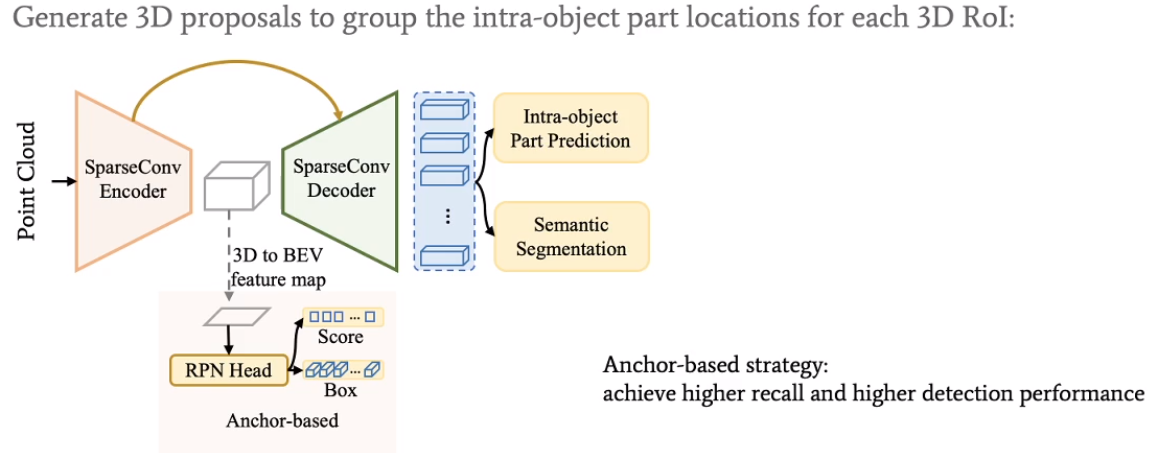
用anchor-based的策略去得到初始的bounding box。此方法能得到更高的检测recall。
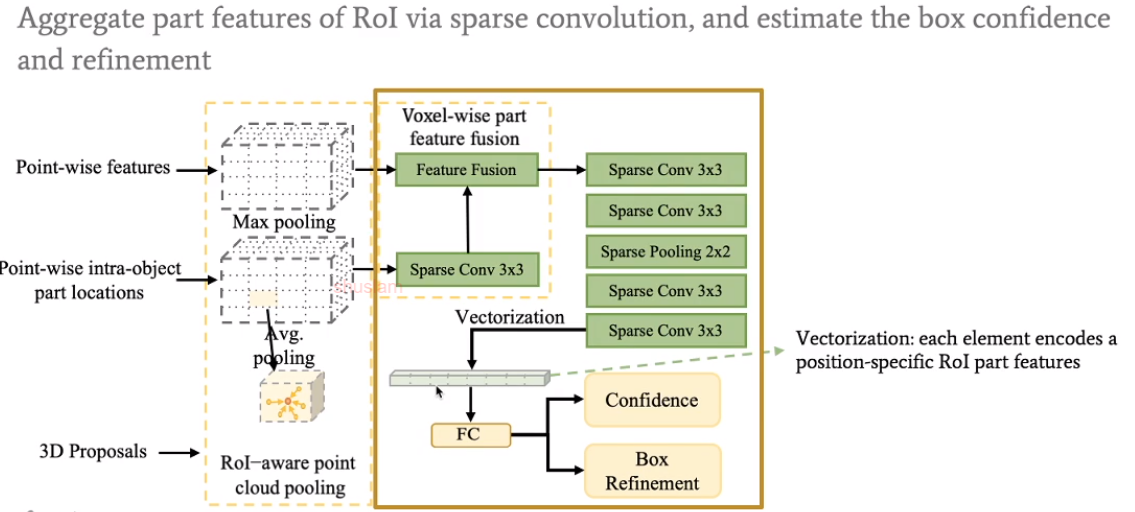
Part-aggregation stage。目的是为了得到3d框的confidence和对框的refine。
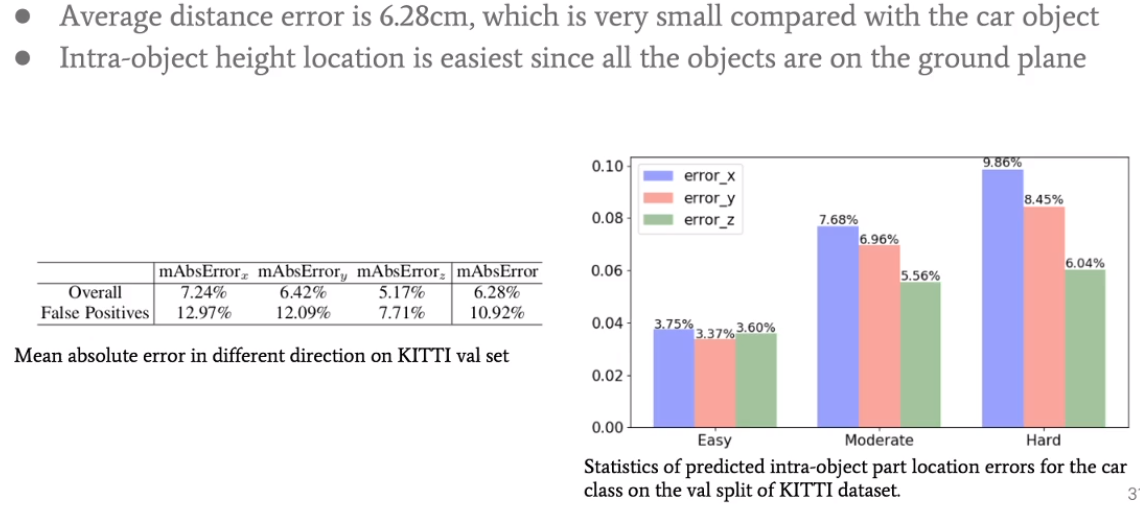
在Z方向的error相对来说是更好的。

存在这不好的case,大部分的原因来源于background,因为毕竟方法只用了geometry的特点,问题诸如花坛一角可能会被当作车子的一部分。
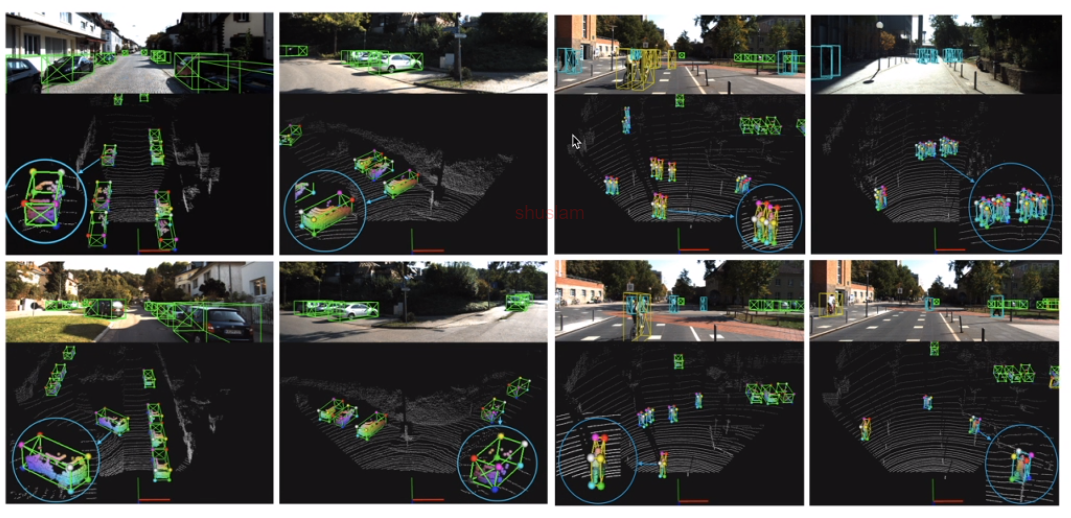
这是一些可视化的效果。

最后讲者介绍了最新的工作,将上述两种方法结合在一起,在feature深度方面进行fusion。

文章的motivation。两种方法各有优点,讲者的思路就是尝试将两种方法的优点深度地整合到一个框架中,更好更高效地学习点云特征。
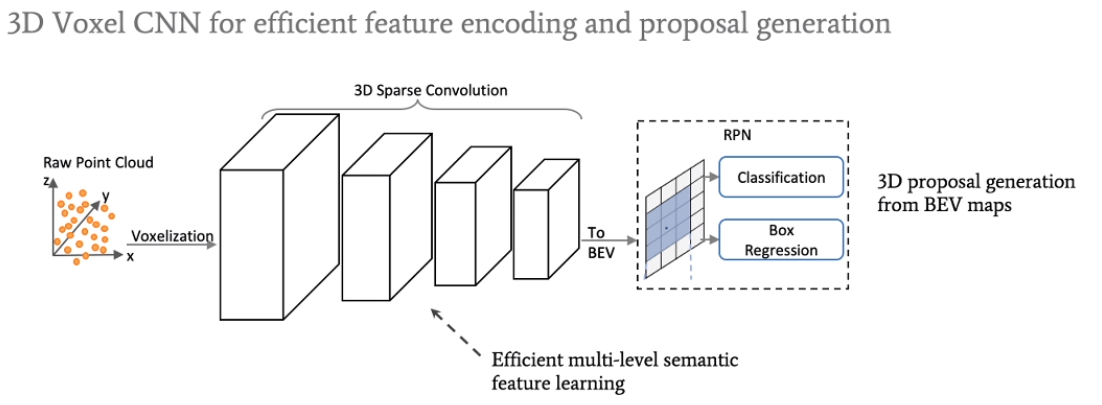
这是voxel CNN部分,对于点云raw point来说,用sampling得到key point。如何将voxel和key point联系起来是需要考虑的问题。
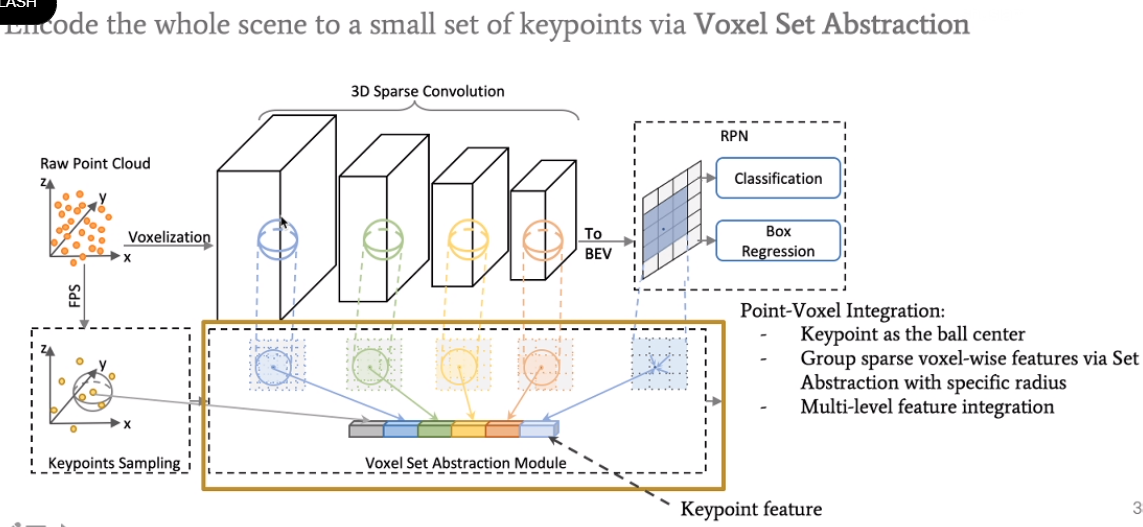
讲者提出了voxel set abstraction module,能得到multi-scale的feature,并且整合了voxel和raw point的方法。这一部分将被用于后续ROI-pooling。
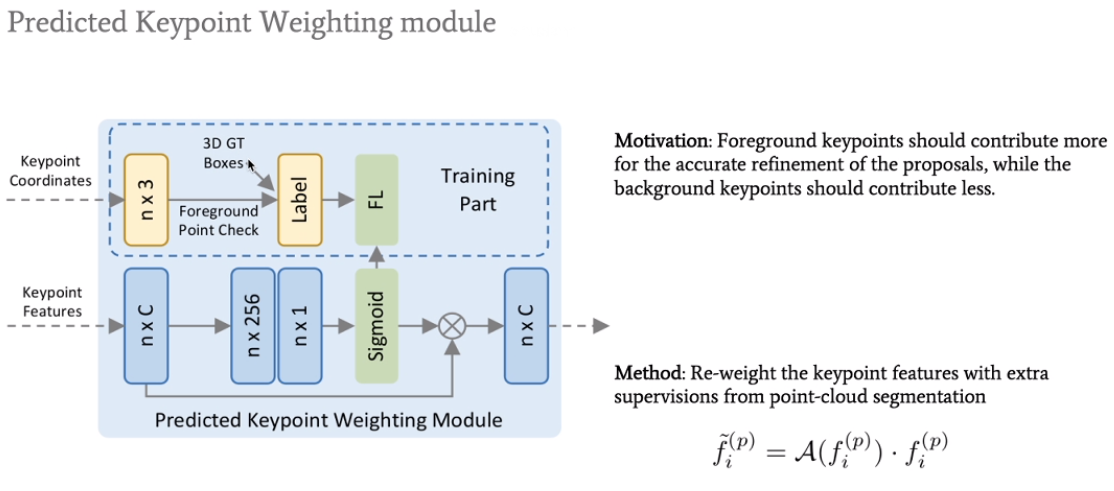
将前景点的feature突出一下,将背景点的feature压制一下。
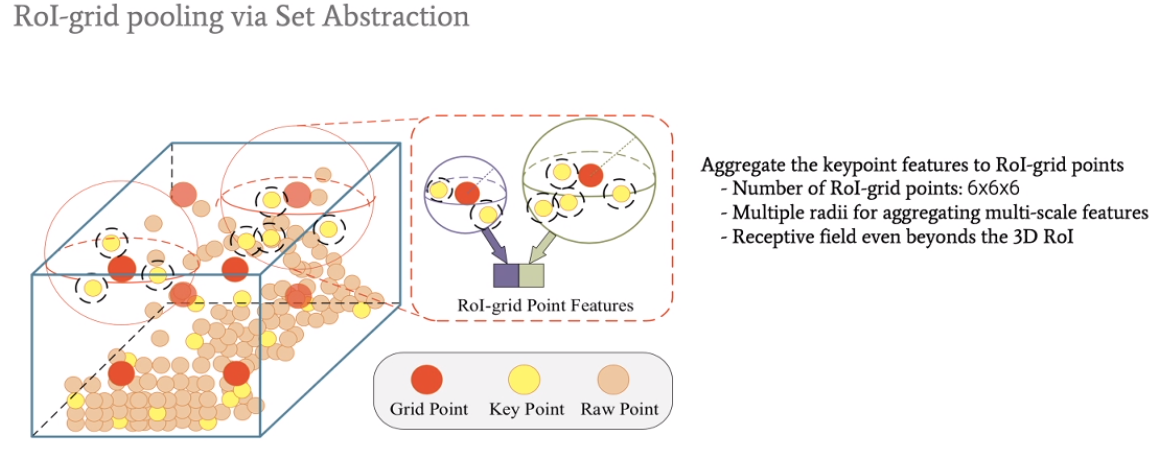
在ROI-pooling基础上提出了ROI-grid pooling
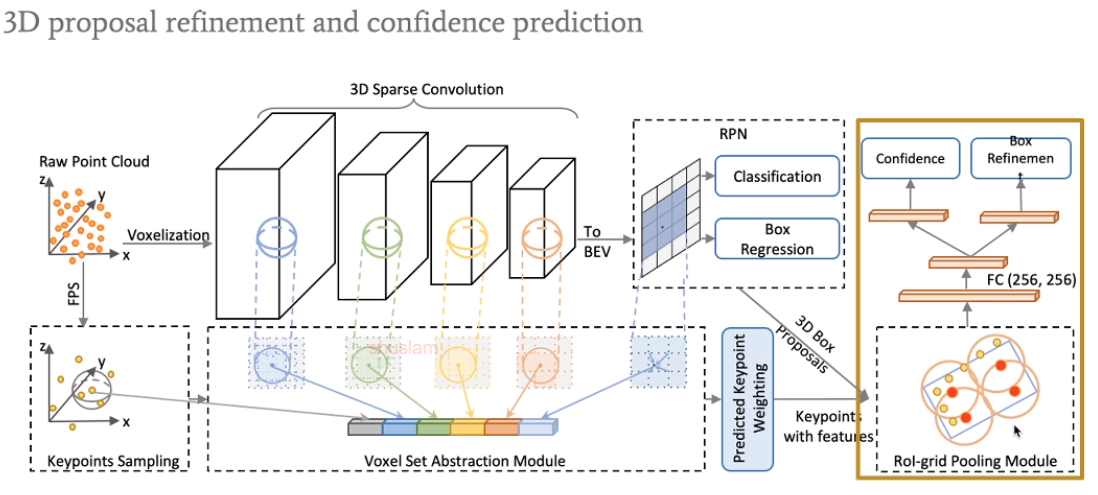
整个方法的框架概览。最终得到bounding box的confidence和对应的refinement。
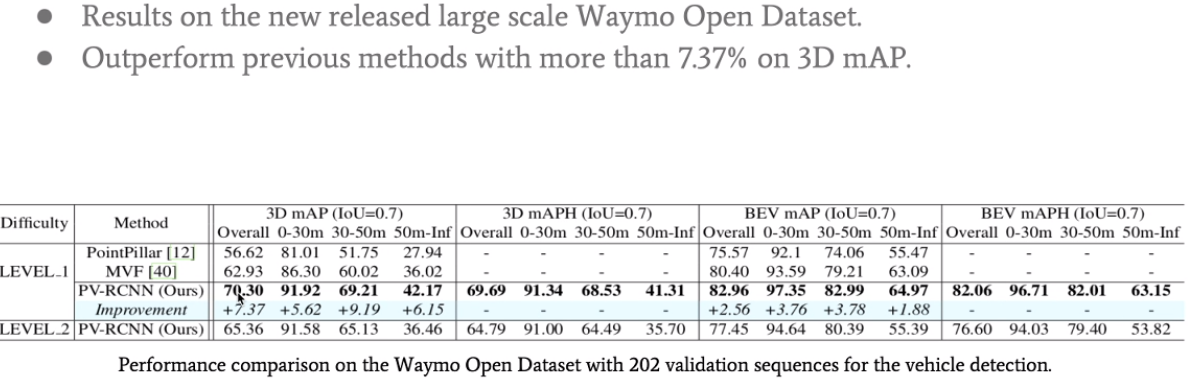
实验在Waymo open dataset上的比较结果。
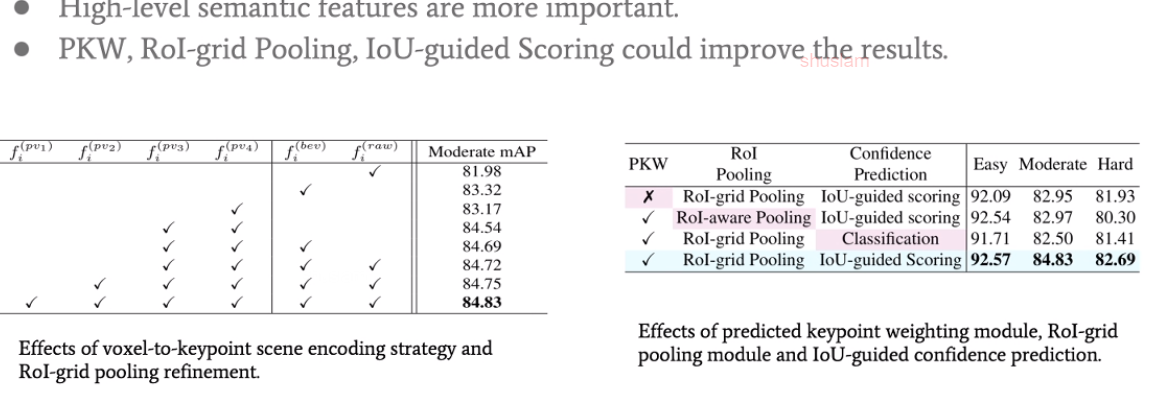
对比、消融试验观察哪一部分的的feature更重要。