深度学习在点云识别中的应用
主讲人一:刘永成,中科院自动化所在读博士,研究兴趣为3D点云处理、图像分割、多标签图像分类等。https://yochengliu.github.io/
主讲人二:李瑞辉,香港中文大学计算机系在读博士,研究兴趣为三维点云处理、三维重建等。https://liuruihui.github.io/
Part 1:深度学习在点云识别中的应用 –刘永成
本次分享主要以思想和方法性内容为主,不涉及具体实现细节。
本次分享的内容框架,Brief review主要是介绍到2019年8月份的该领域进展。

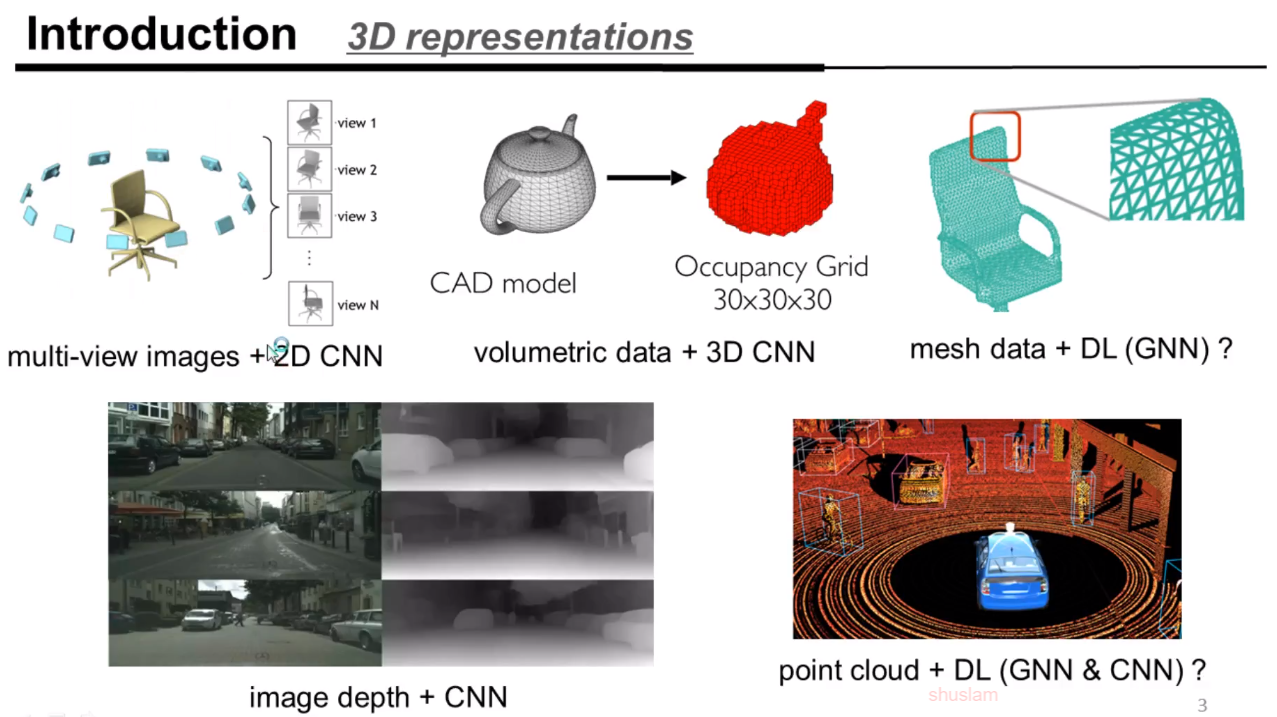
3D表示有多视角+2D CNN(存在自遮挡和多图消耗资源的不足)、体素化表格(受制于划分精度)+3D CNN、mesh(有点和边)+DL(GNN)、图像深度(2.5维)+CNN和纯点云+DL(GNN&CNN)。基于纯点云数据是目前比较open的问题
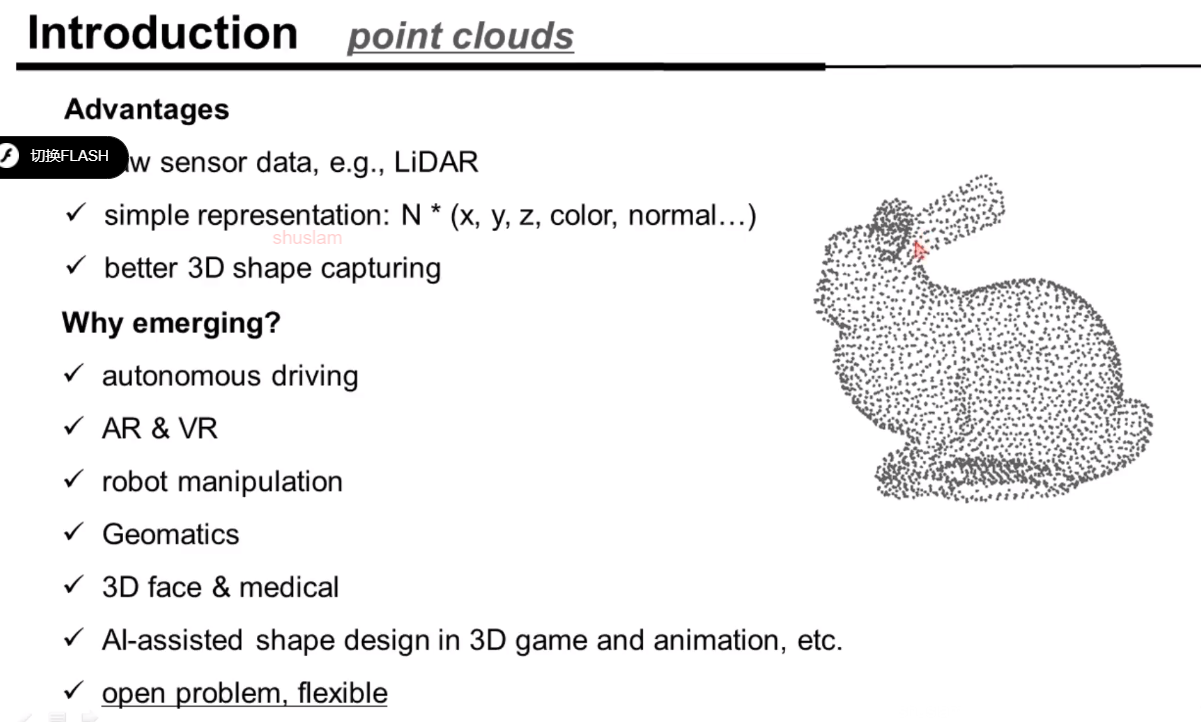
点云的优势
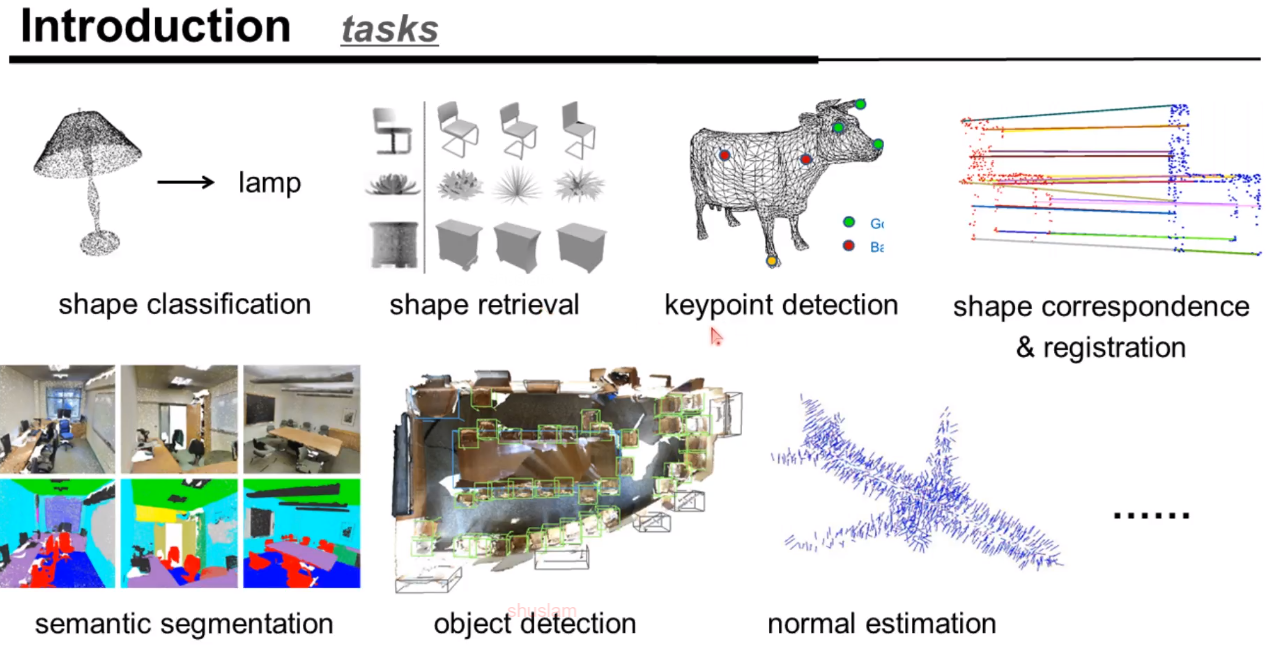
基于纯点云数据的任务类型
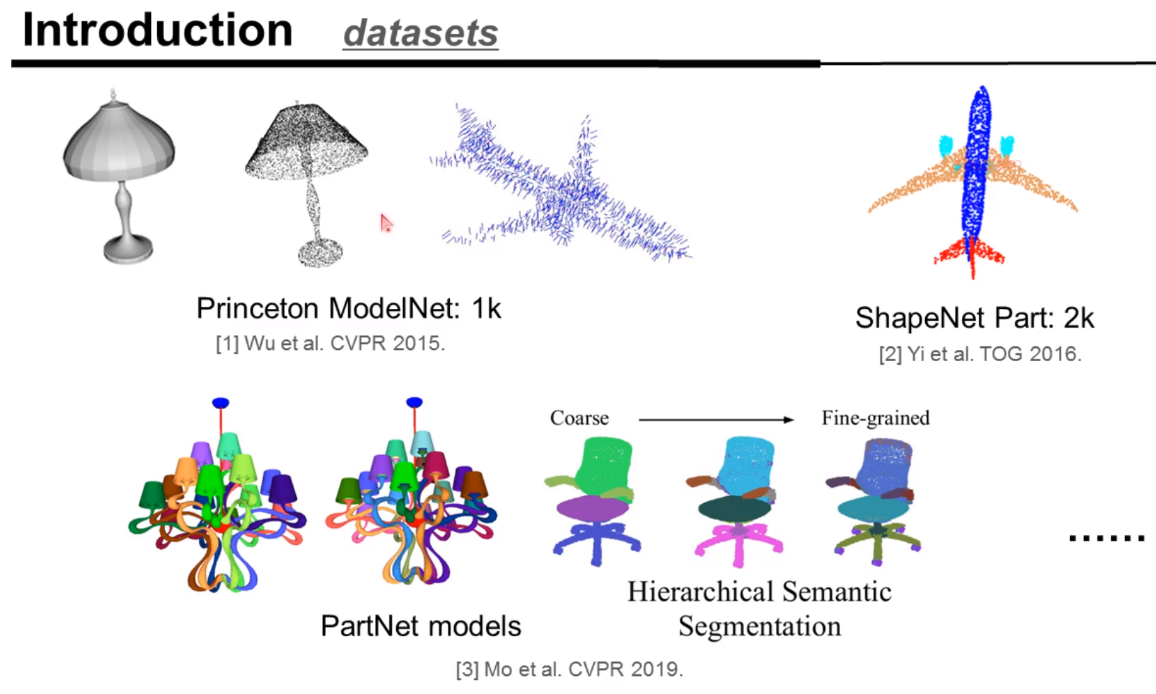
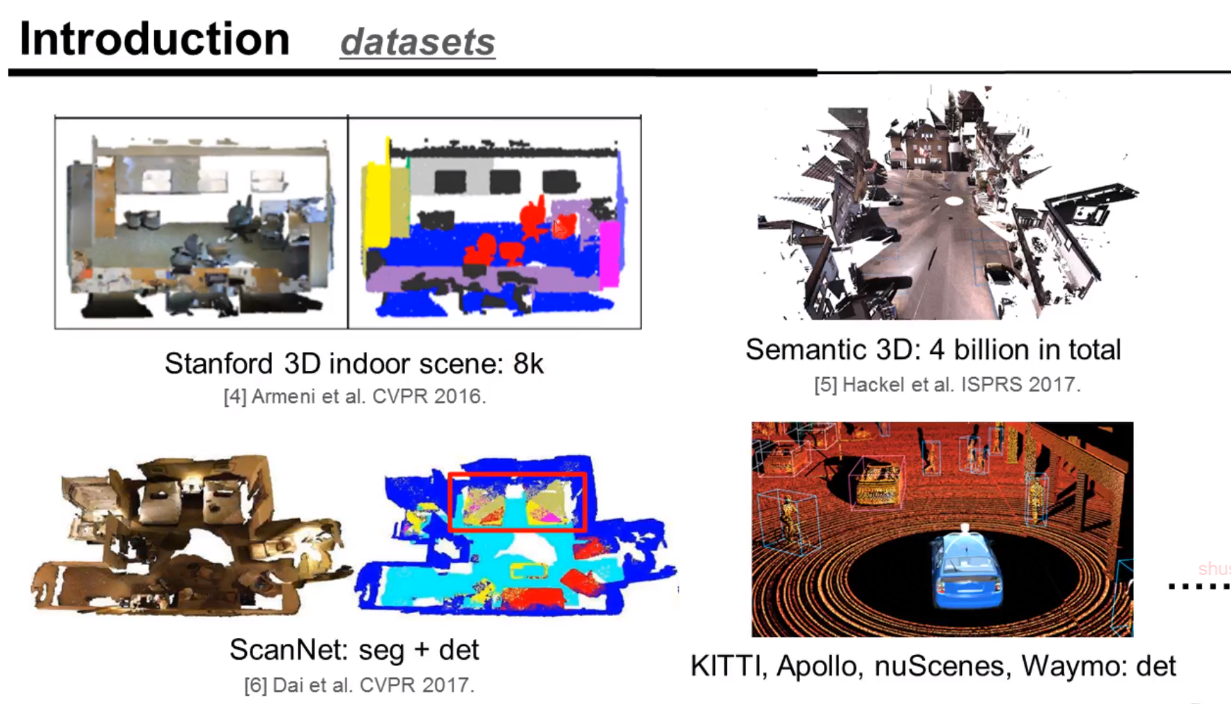
点云的数据集介绍。其中PartNet对未来机器人领域的推动性会比较大
场景类型的点云数据集:
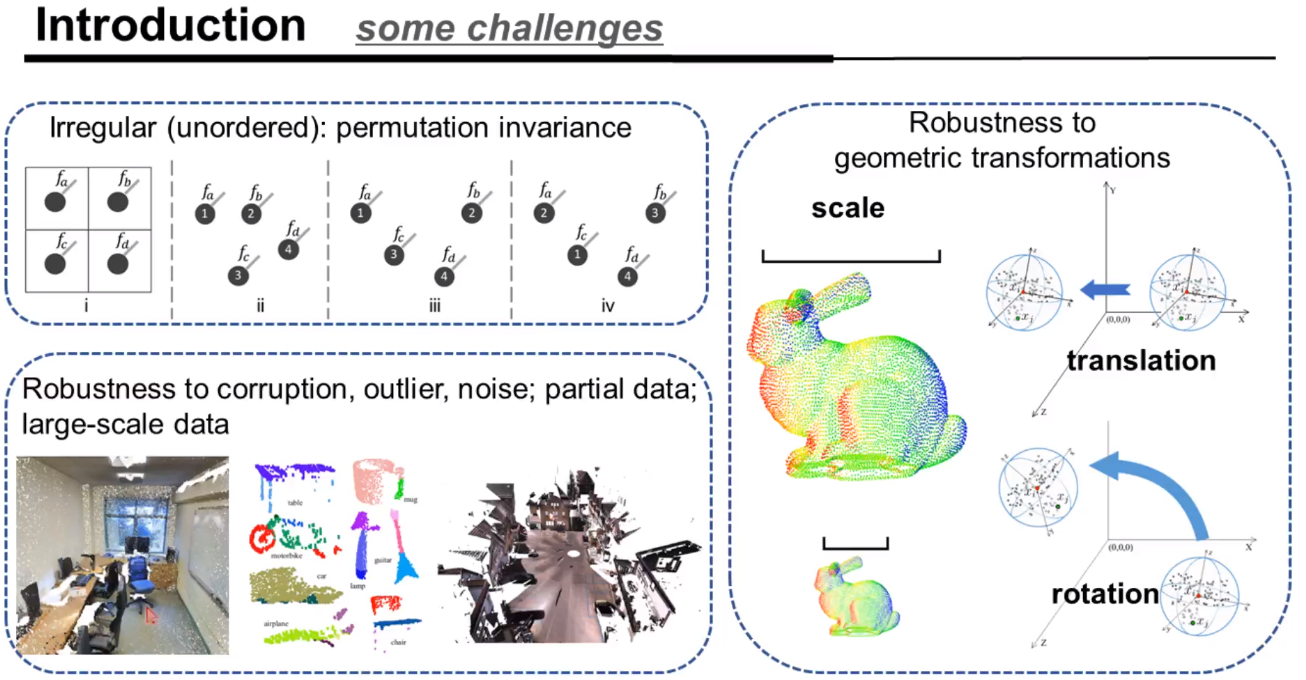
对于纯点云数据来说存在的一些挑战:Irregular(unordered)、robustness to geometric transformation、robustness to corruption, outlier,noise, partial data and large-scal data
接下来综述一下最近的工作
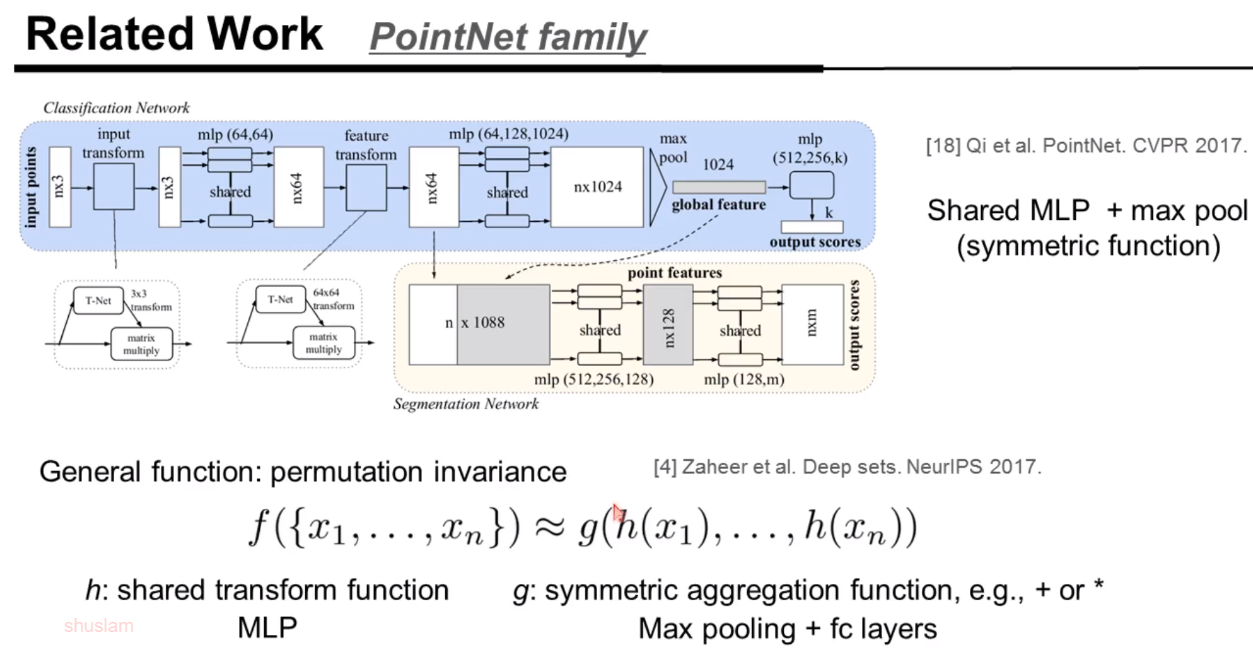
首先致敬PointNet
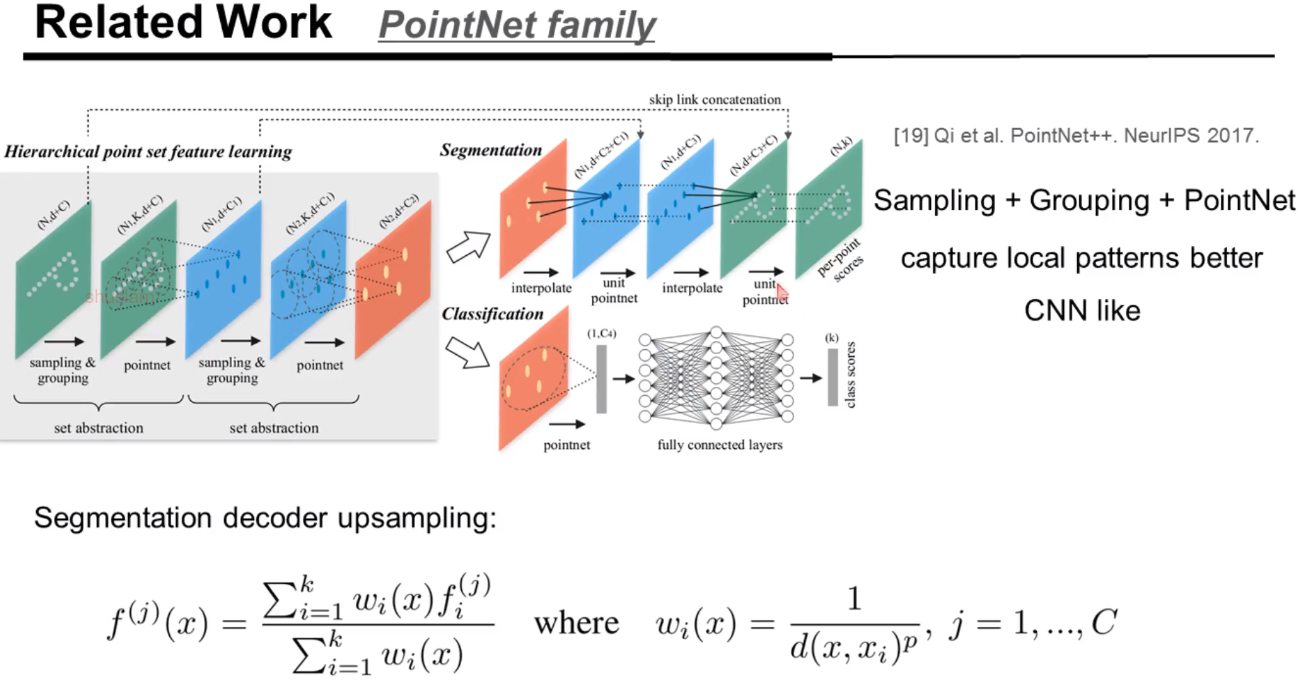
PointNet++改进PointNet无法提取局部领域信息的不足
后续很多工作都是在PointNet和PointNet++基础上做的。
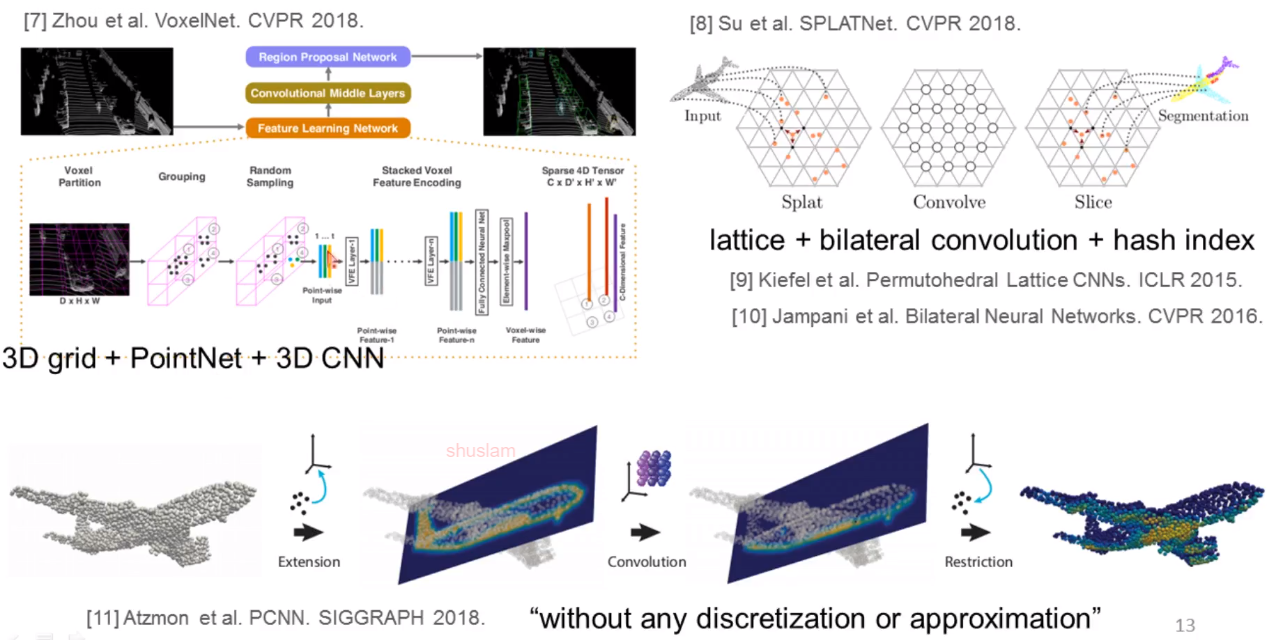
之前的方法都多用到了手动处理(Voxel或投射)和超参设置的过程,接下来介绍用自动学习的方法去思考
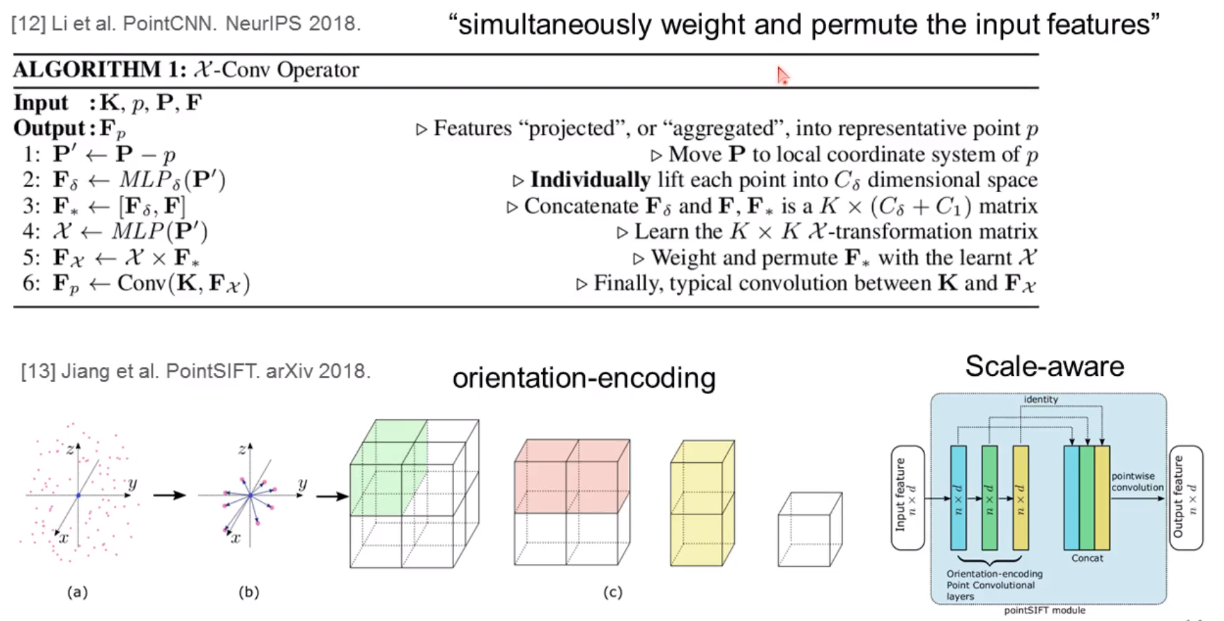
还有一些其他思路的方法
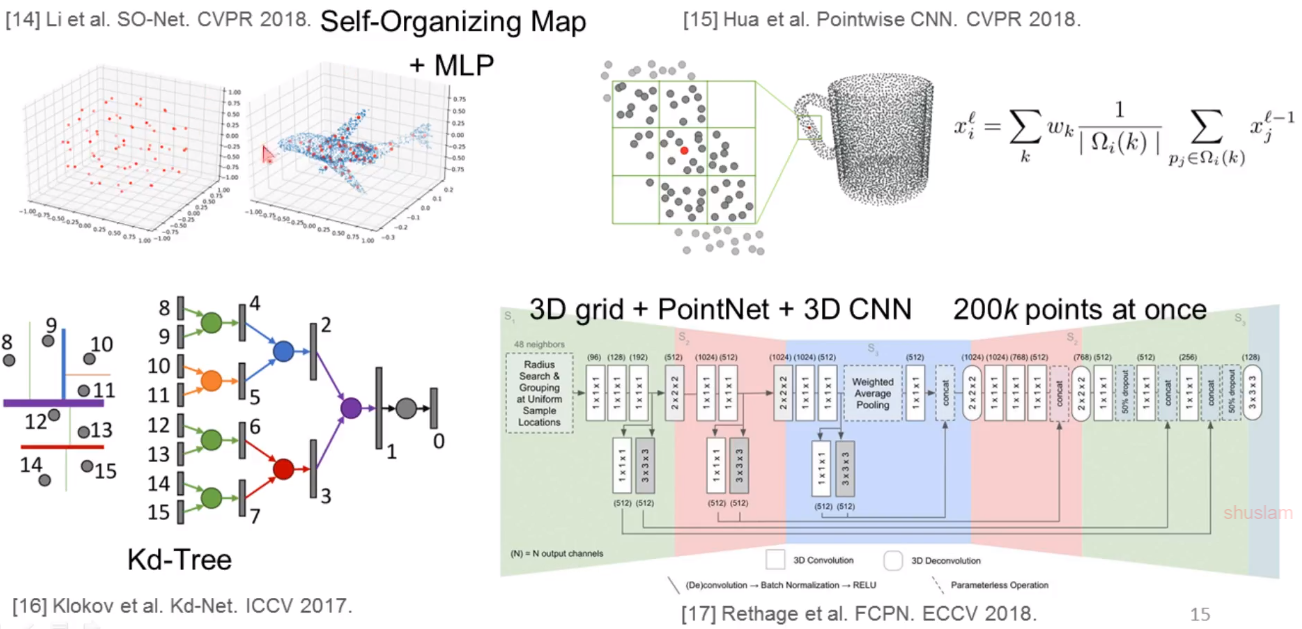
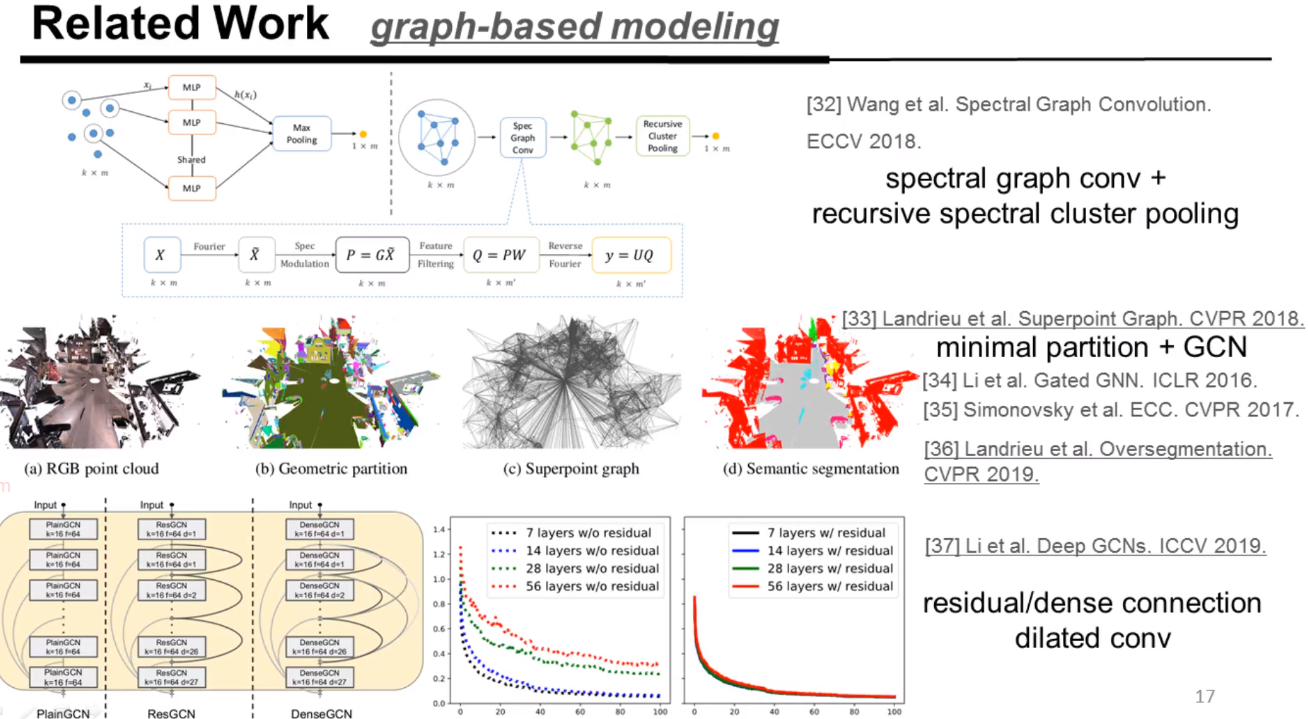
有些研究者开始考虑用图卷积方法去思考这个问题
空域图卷积
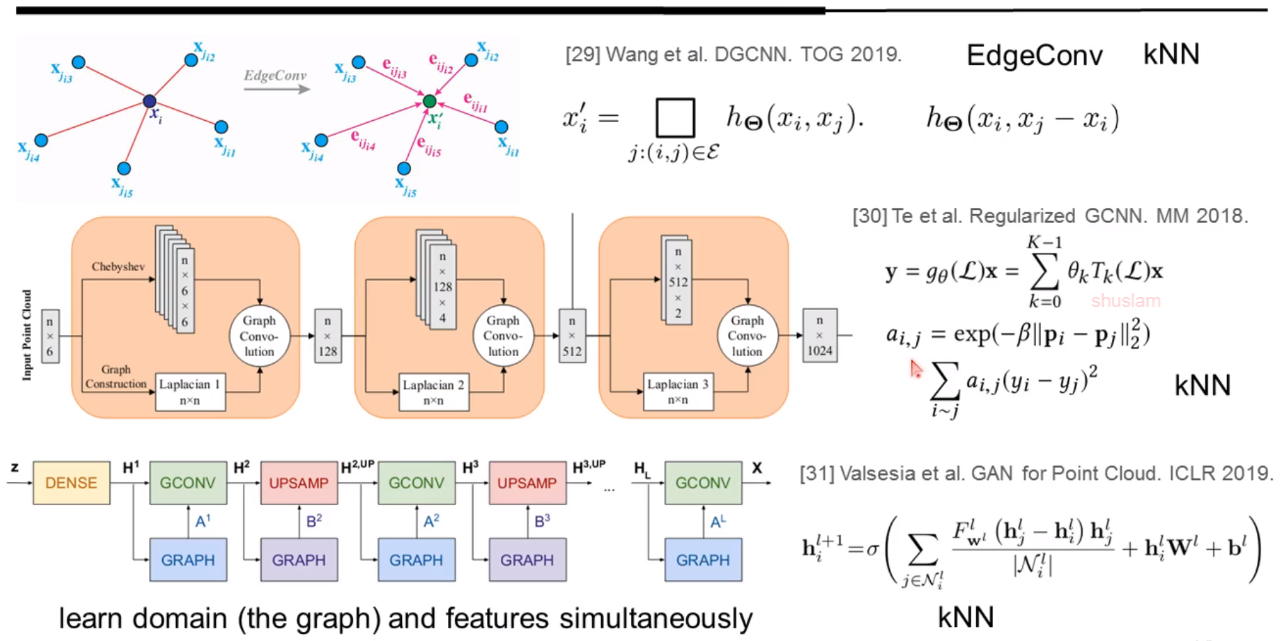
谱域图卷积
既然2D图像有直接适用于图像结构的卷积方法,那么能不能直接设计出一种合理的适用于3D点云的卷积方法呢?
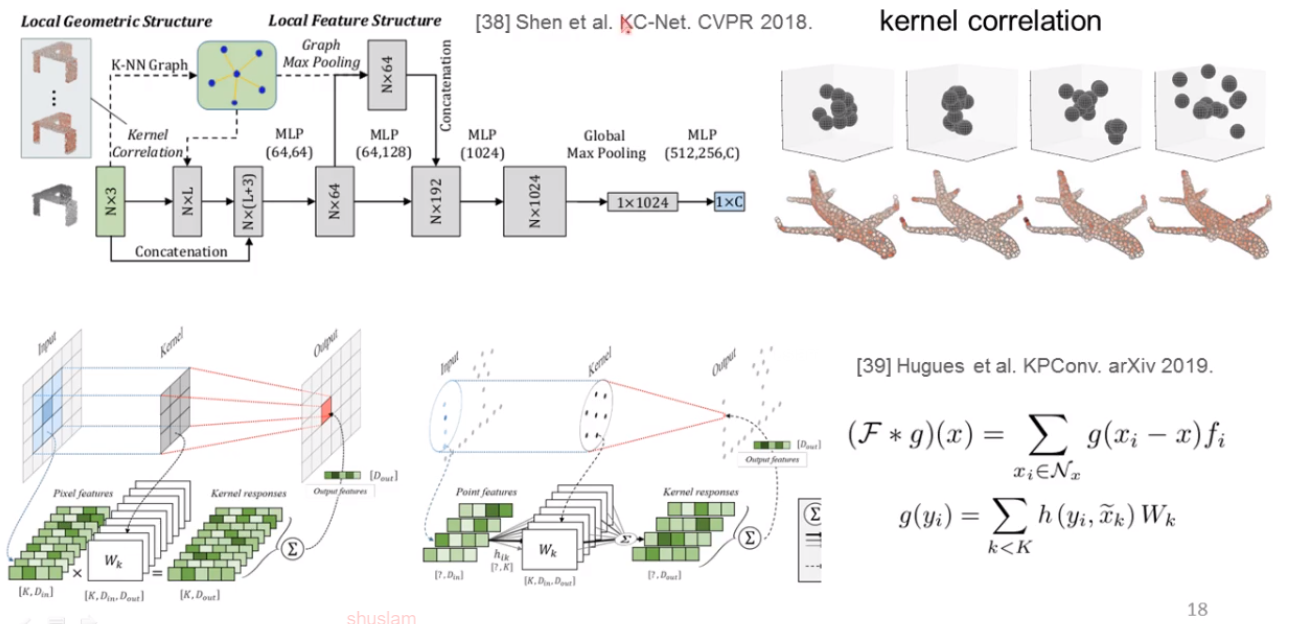
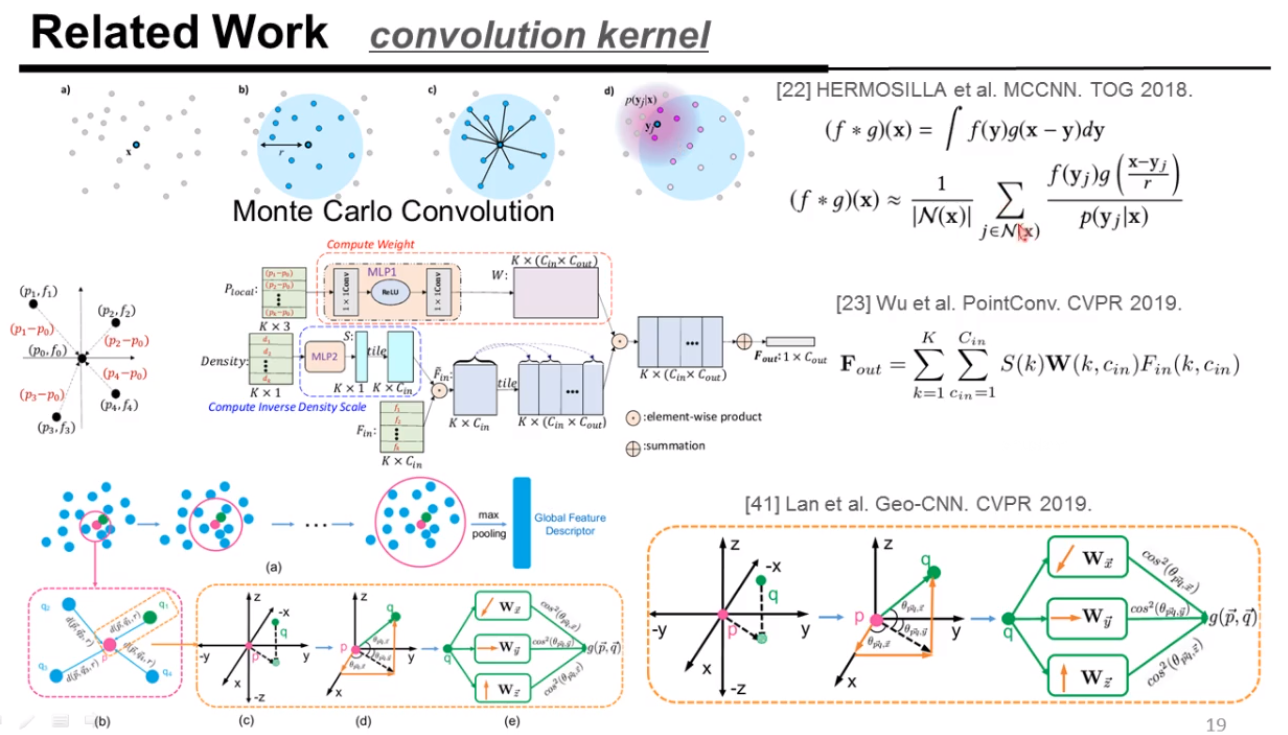
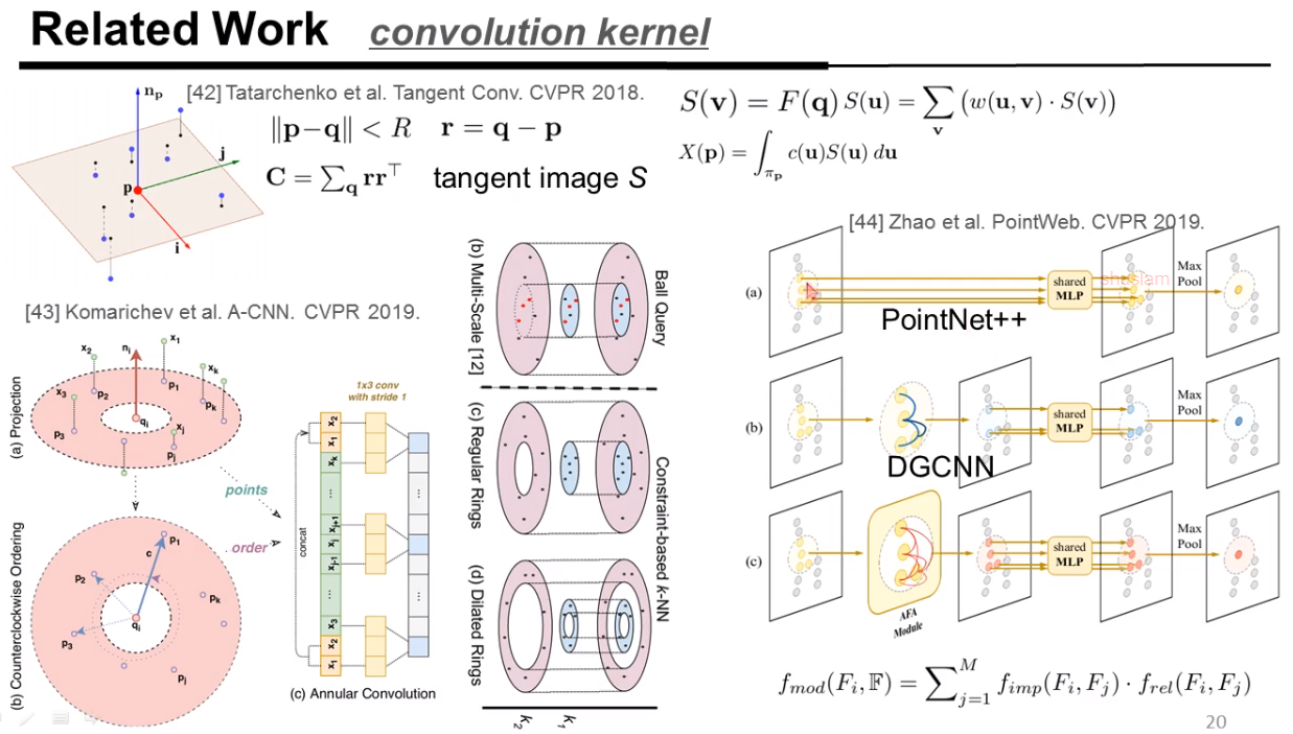
对于点云挑战,还有一个是鲁棒性问题
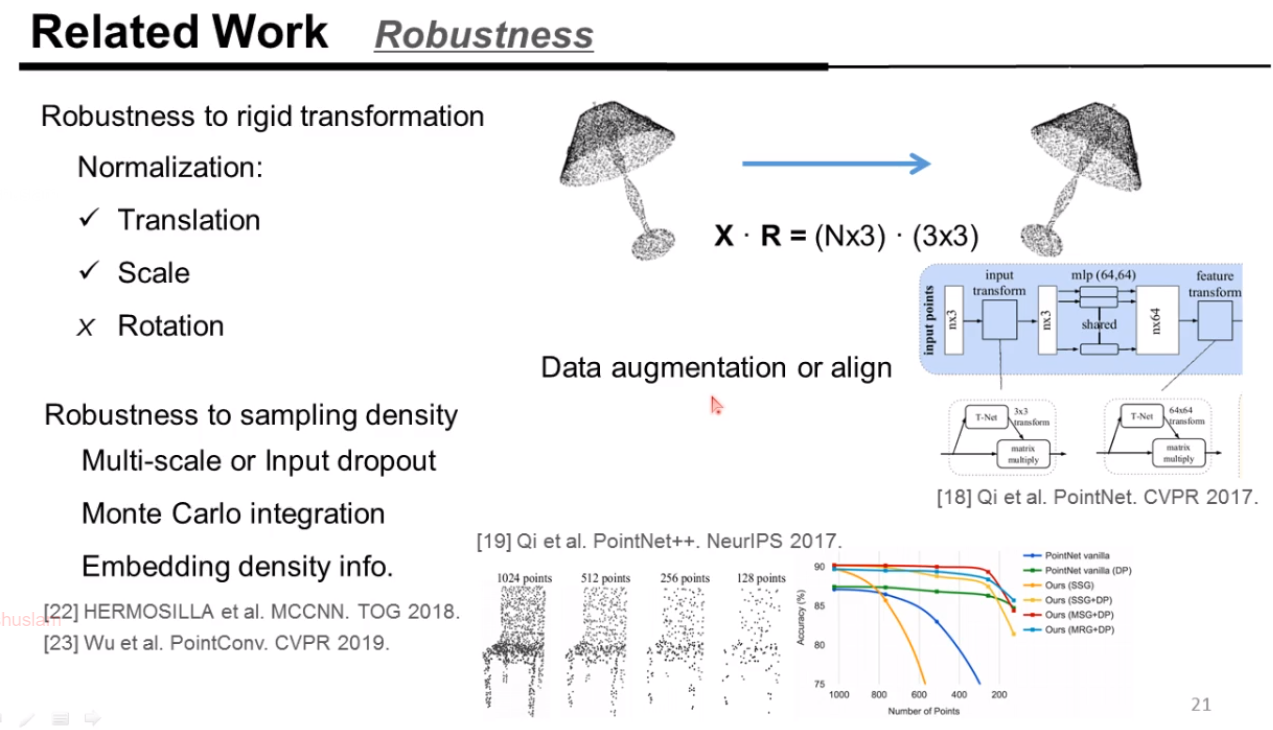
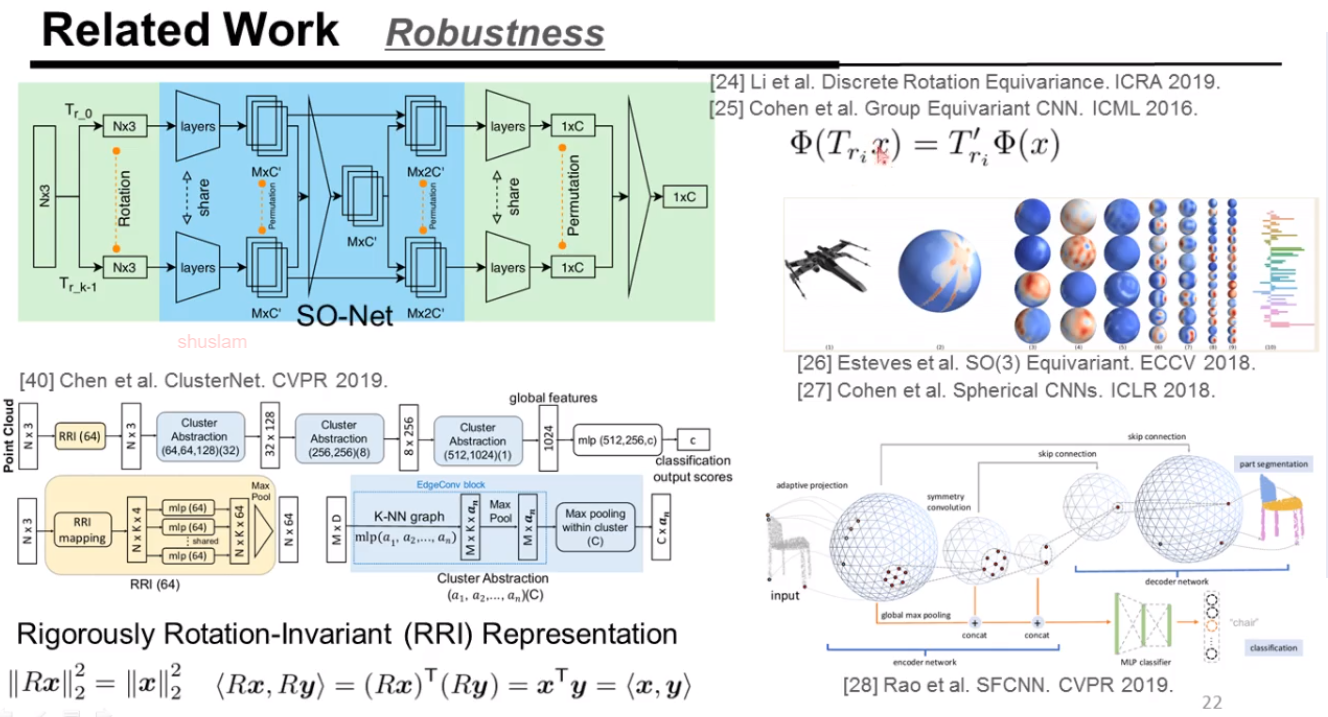
对于旋转不变性,有一些工作:
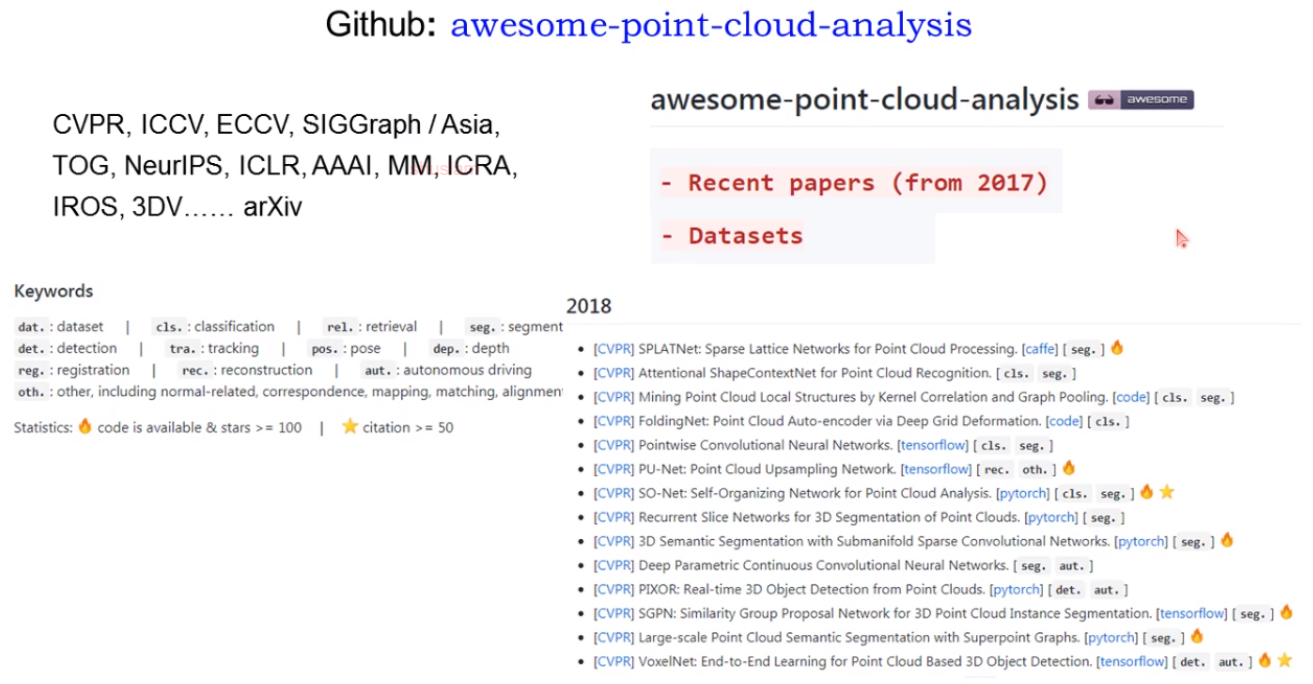
讲者在github上总结了点云深度学习领域工作的分类
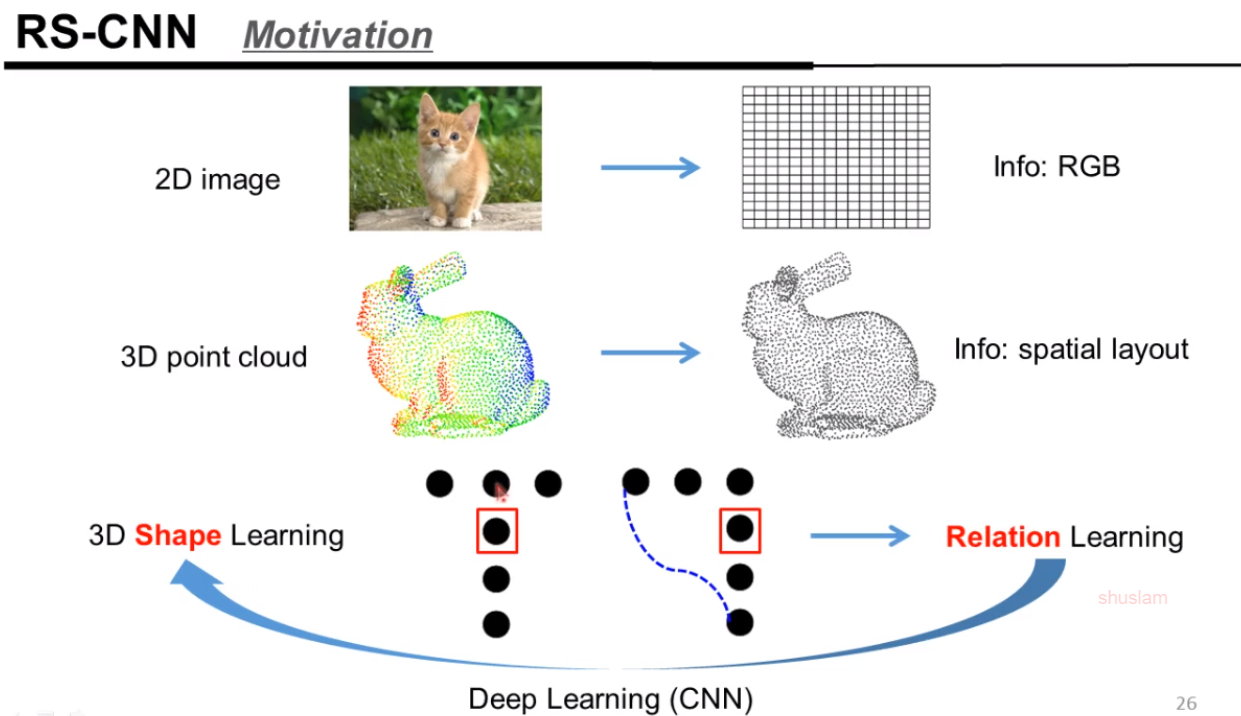
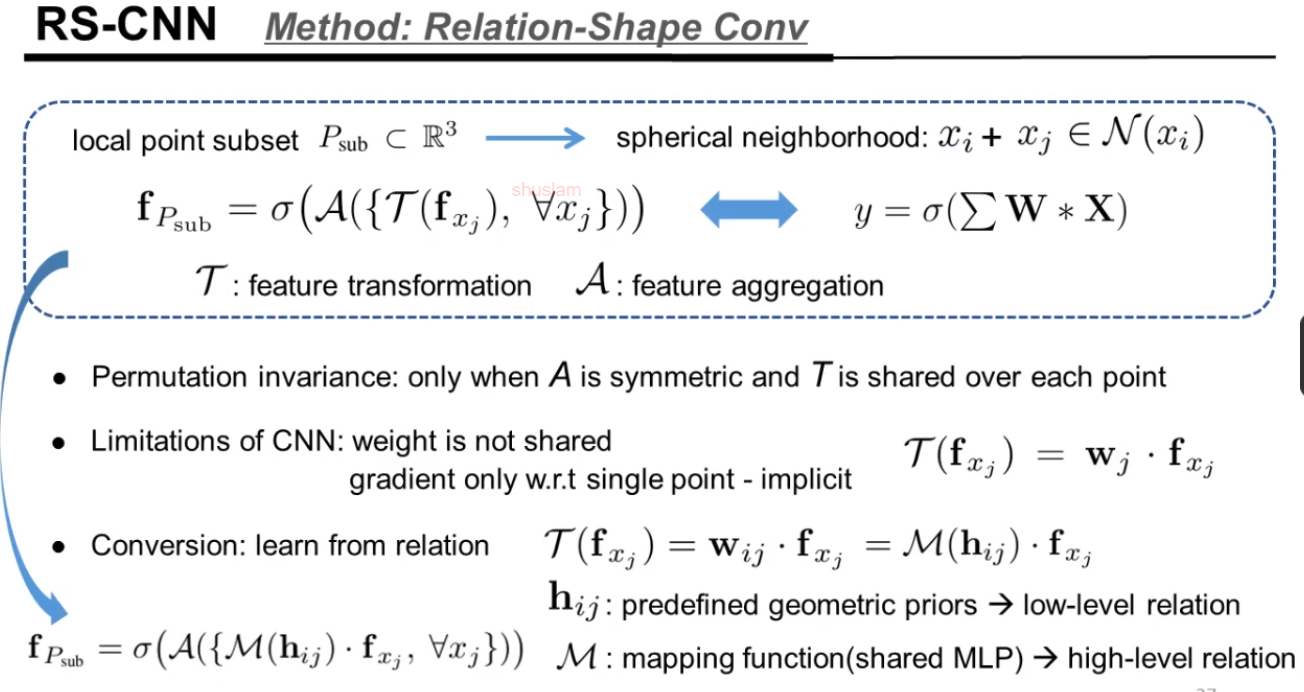
讲者的工作: RS-CNN

他的研究motivation
方法的主要思想
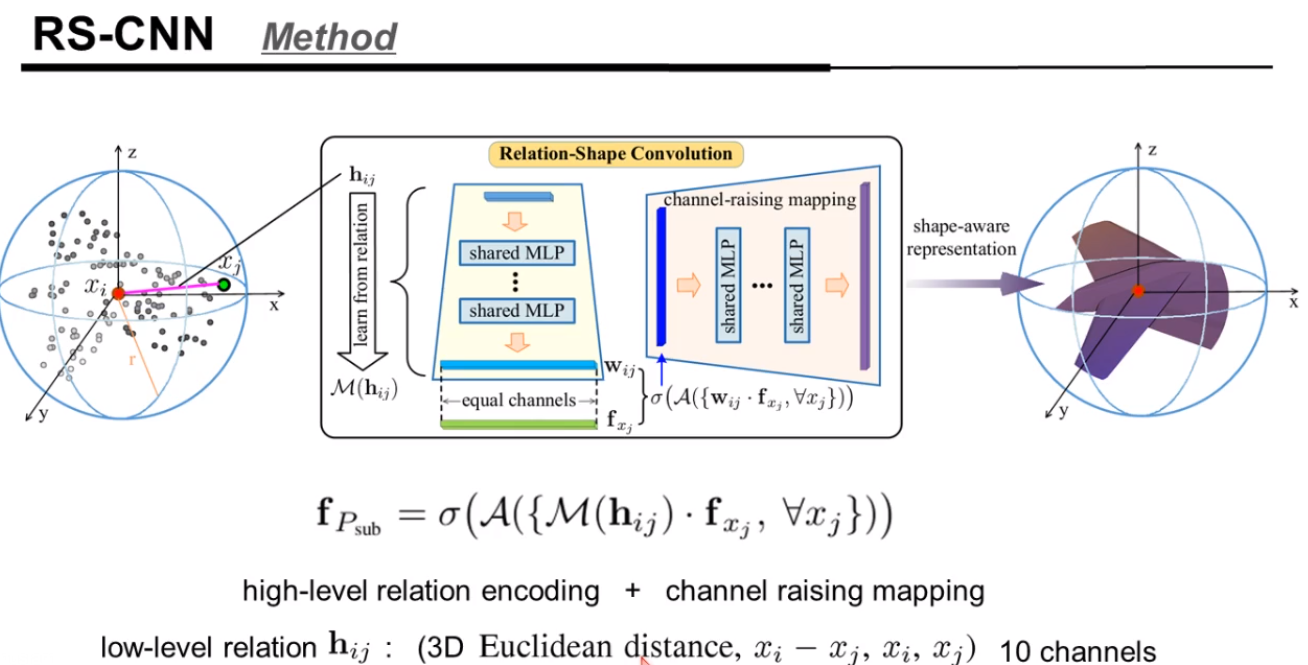
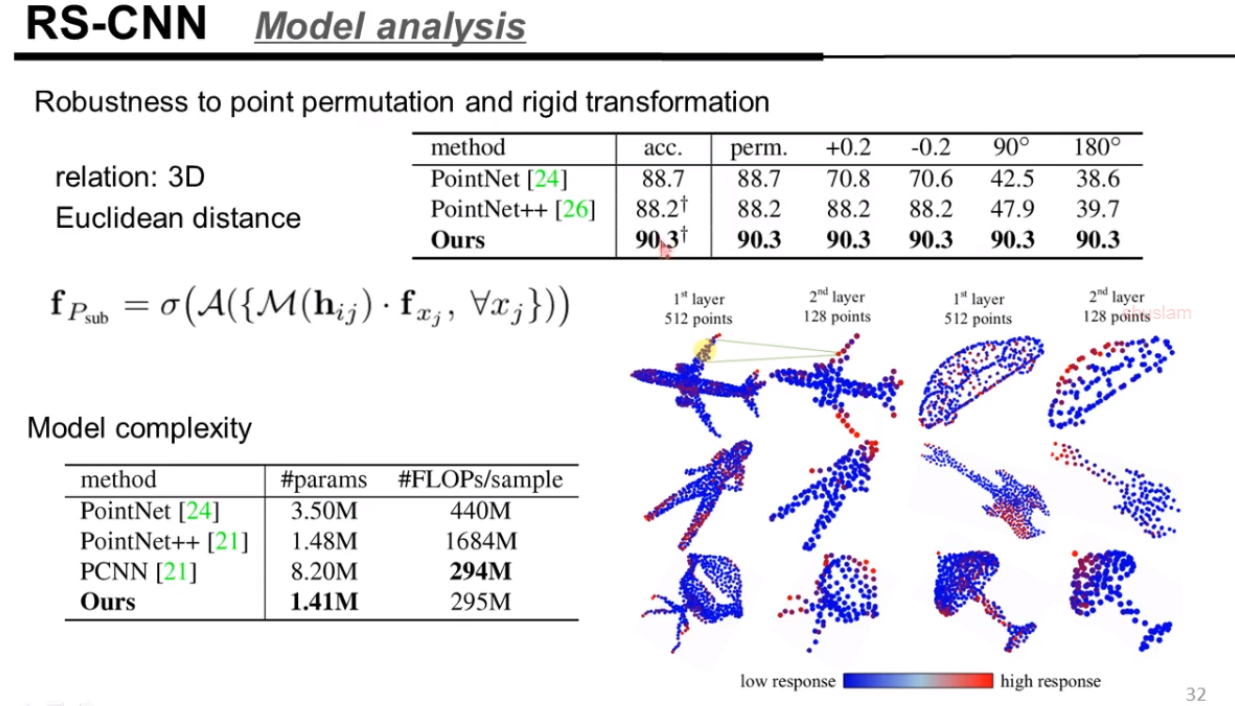
几何不变性的实验
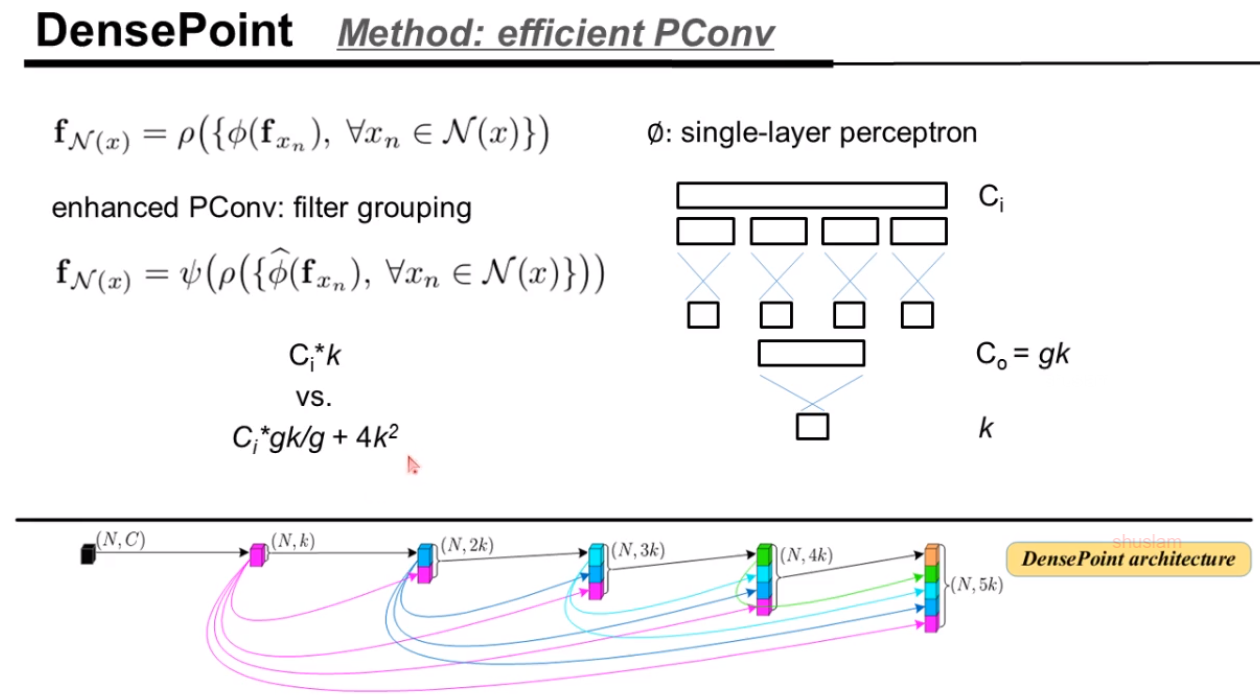
工作二:DensePoint

文章的motivation

考虑的思路:
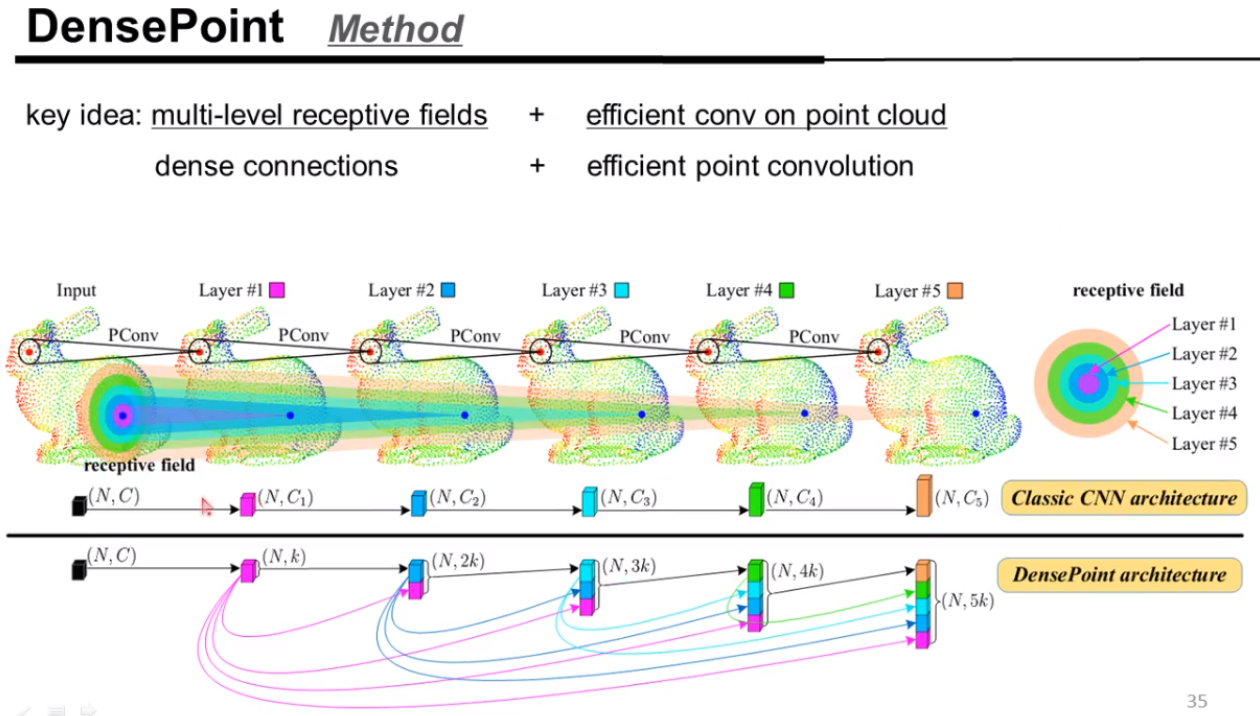
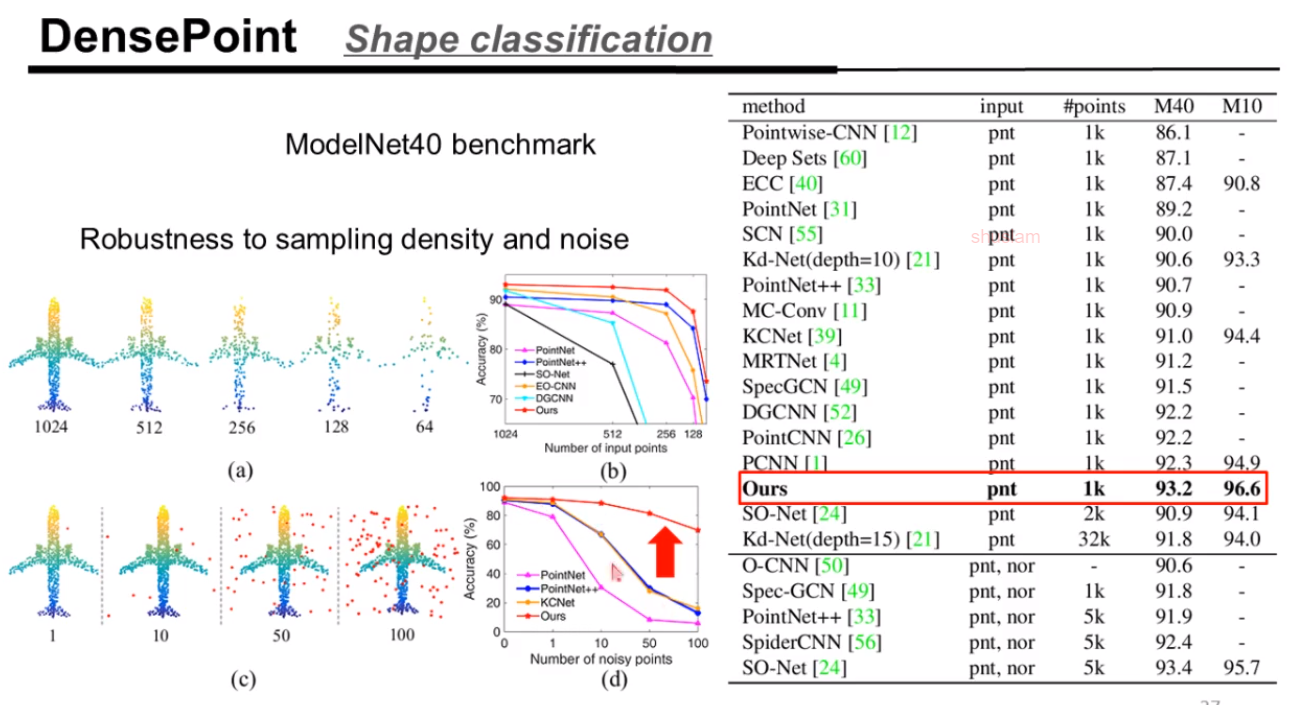
实验效果结果,DensePoint对噪声点的鲁棒性有较好的效果。
讲者的展望:

Part2:PointAugment: an Auto-Augmentation Framework for Point Cloud Classification –李瑞辉
分享内容的框架

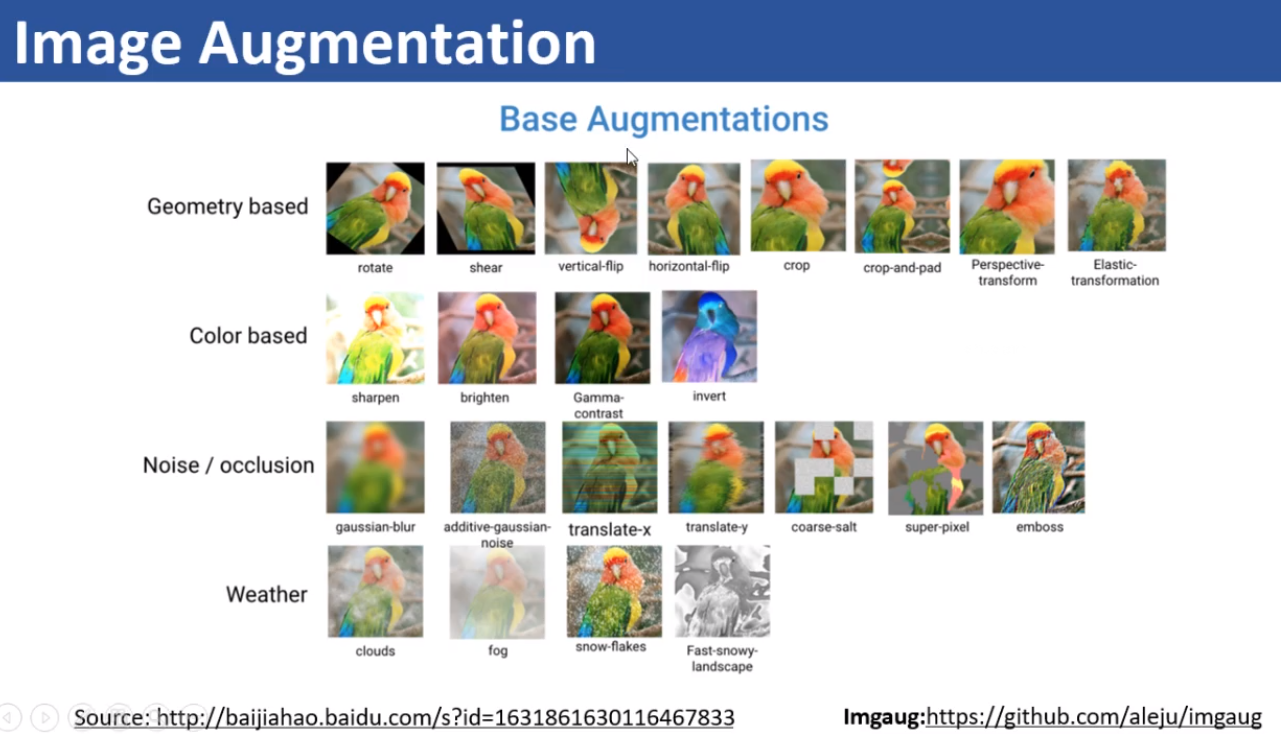
目前普遍使用的Data Augment(DA)方式

简单的数据增强方法的介绍
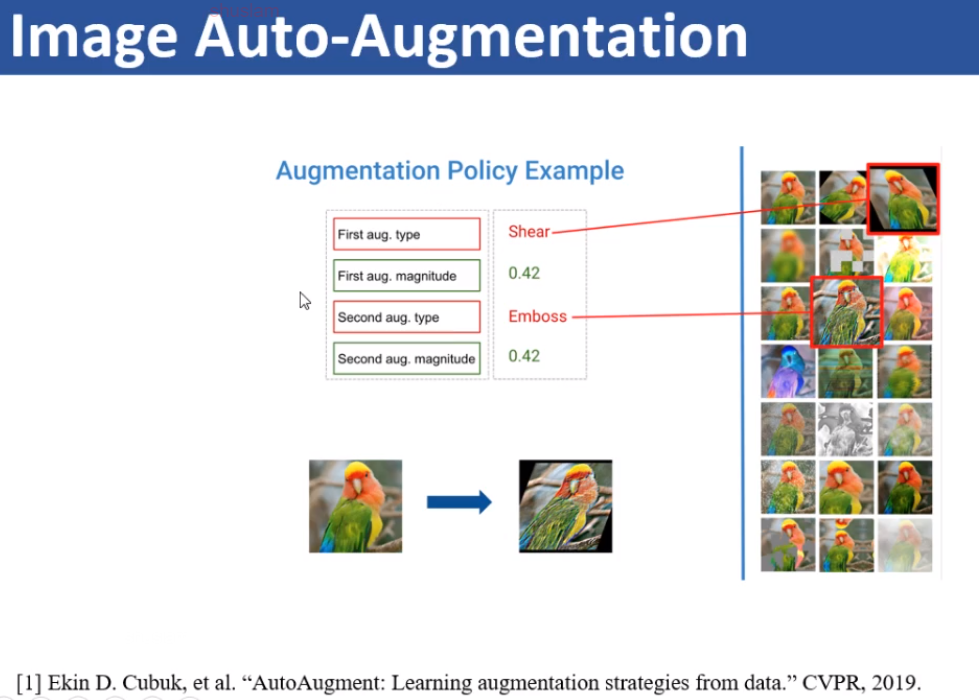
google在2019年CVPR出了该领域第一个paper做数据增强方法的分类和从数据自动判断增强方式
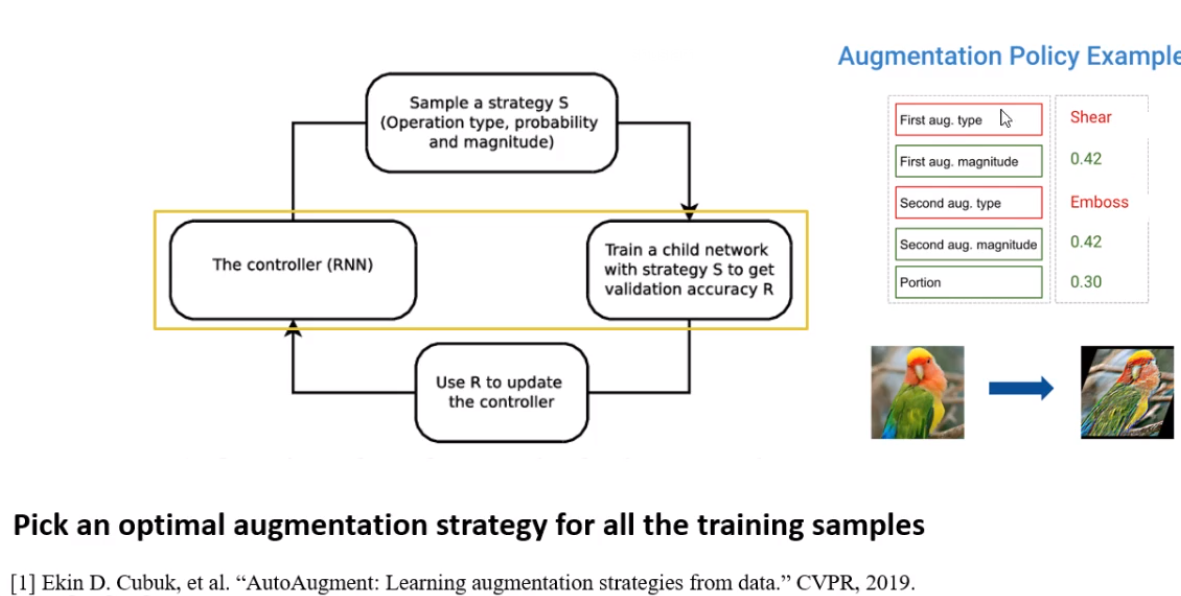
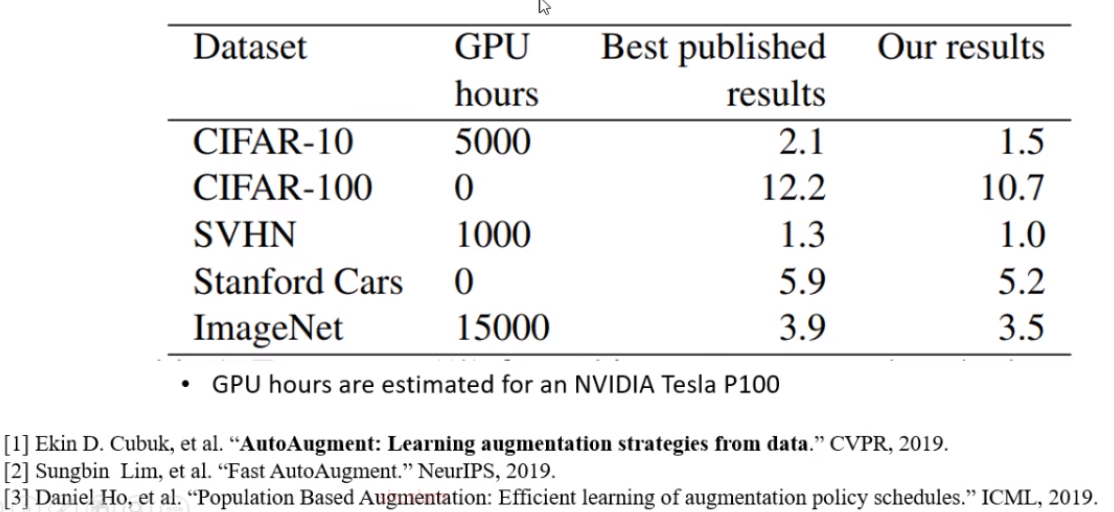
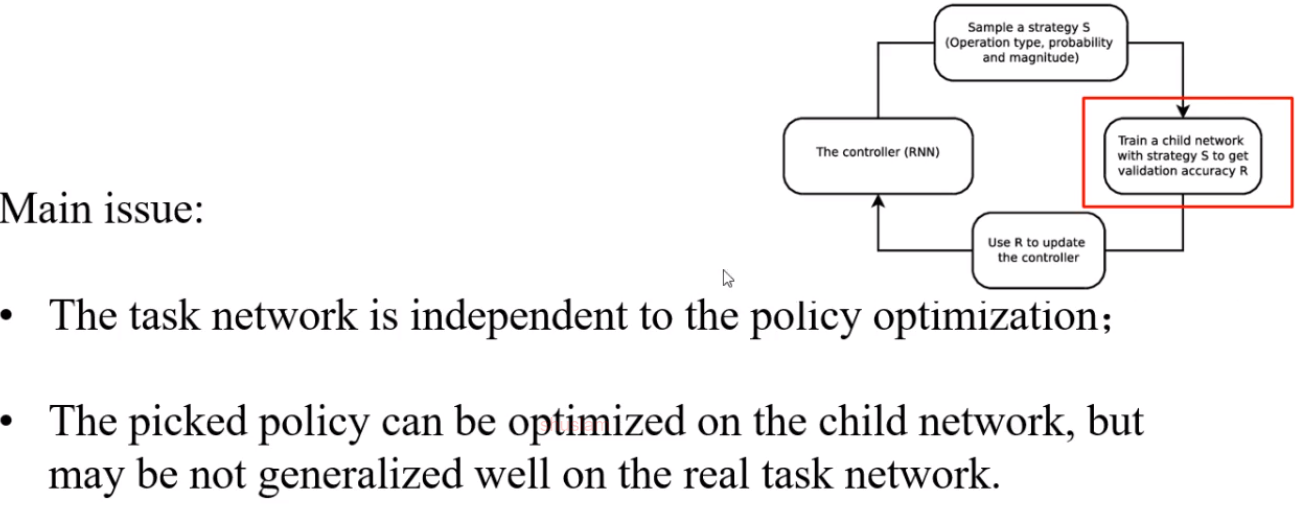
上述方法存在的主要问题:
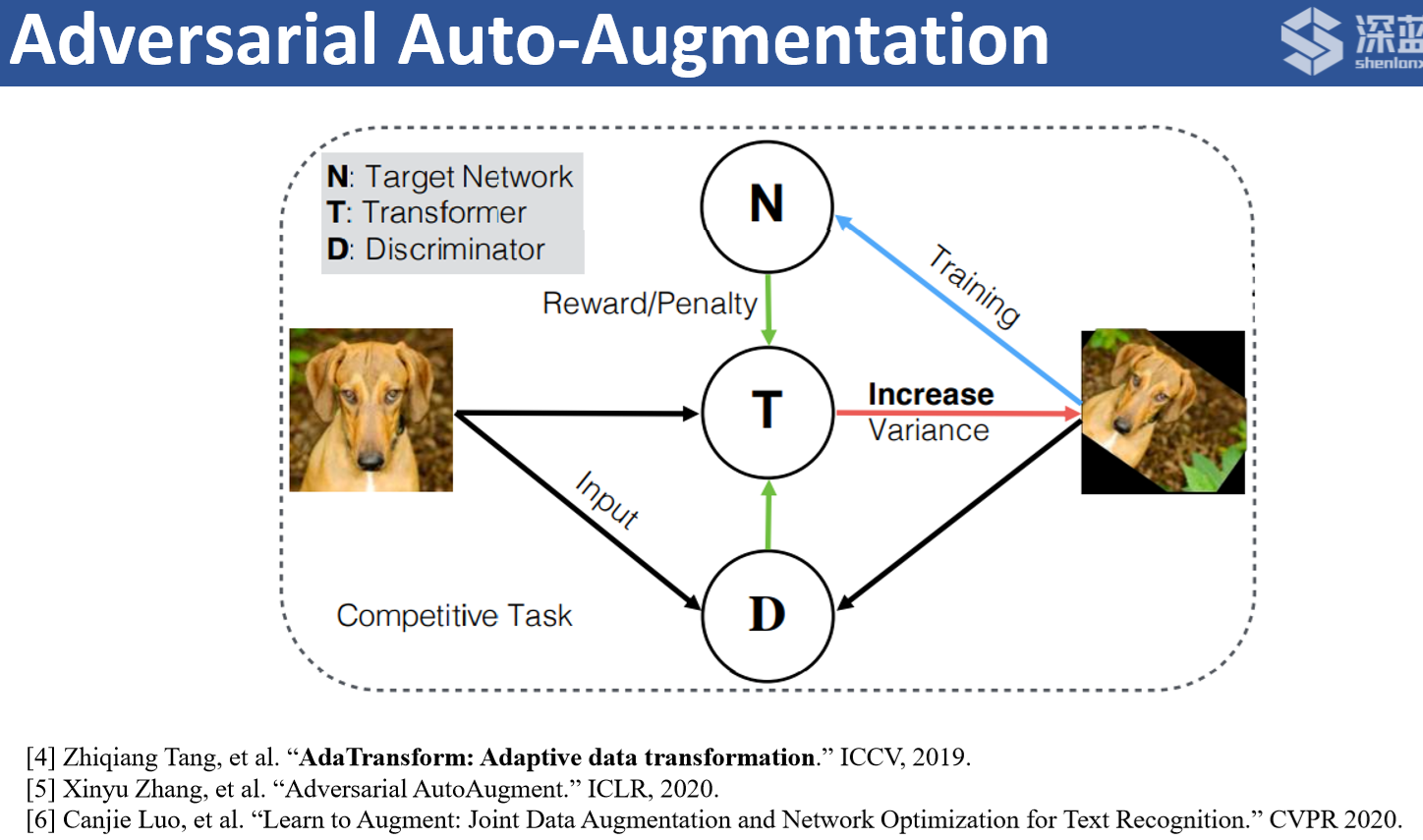
基于对抗方式的自动数据增强
讲者的工作在于对点云数据做自动数据增强
motivation

传统的DA方式:Rotation, Scaling, Translation, jittering,这种处理方式是和training分开的。

讲者工作的主要流程思想,joint optimization可以动态调整augmentation sample的困难度。
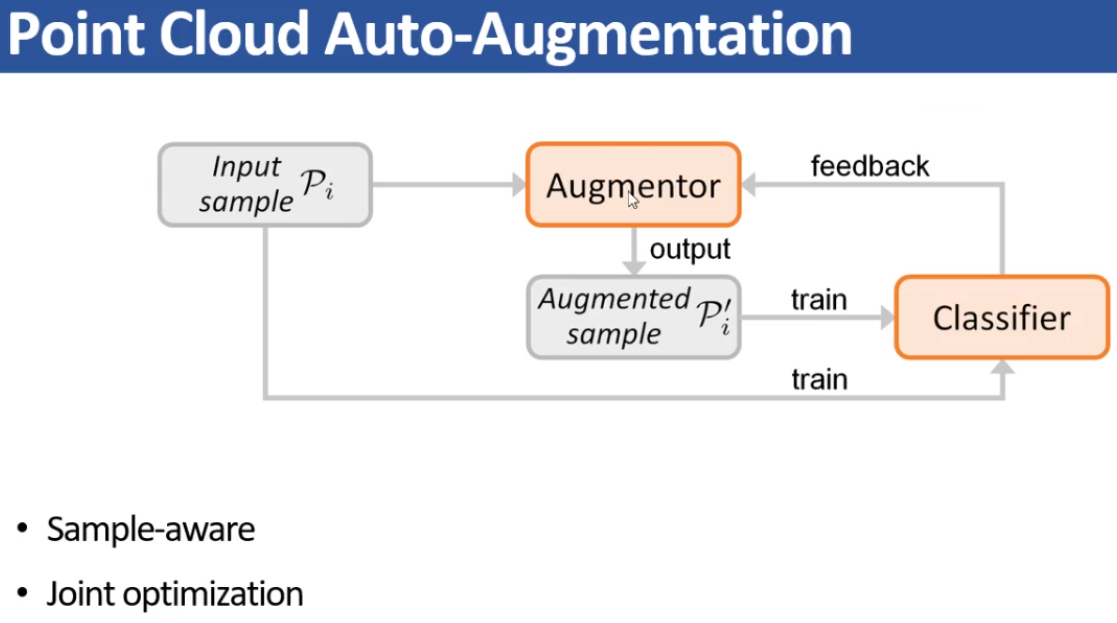
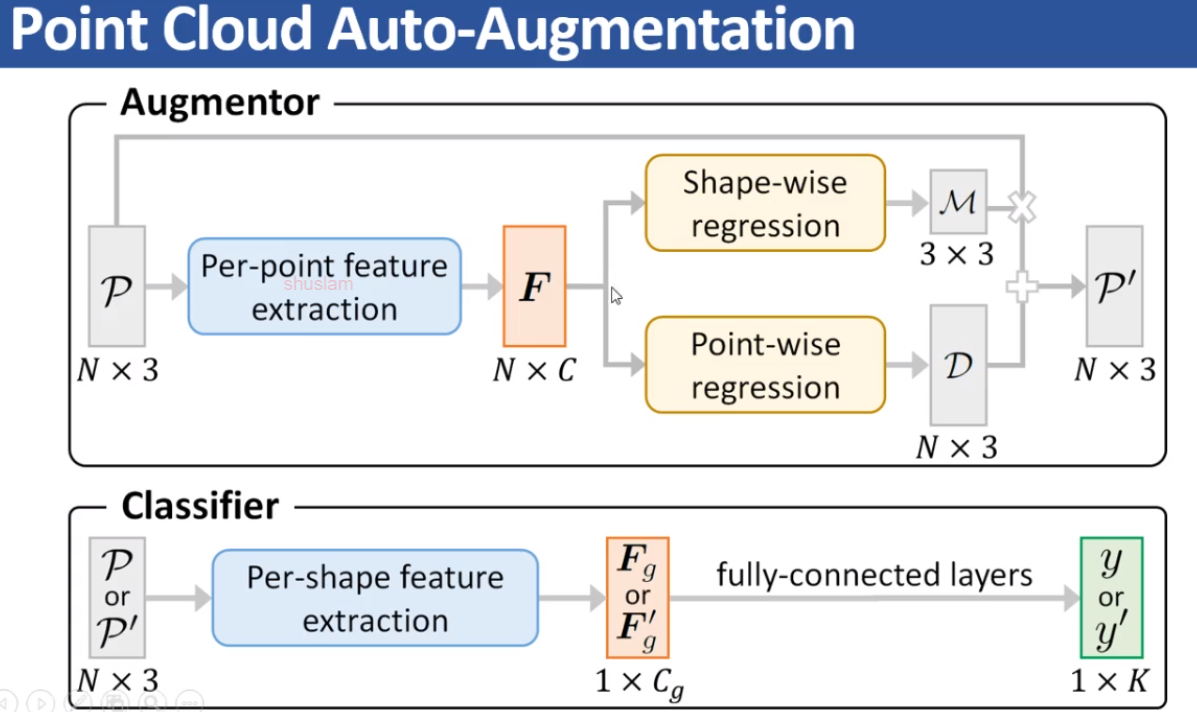
上述的feature extraction是可以用现有任何方法去替换的,加下来基于PointNet给个简单例子
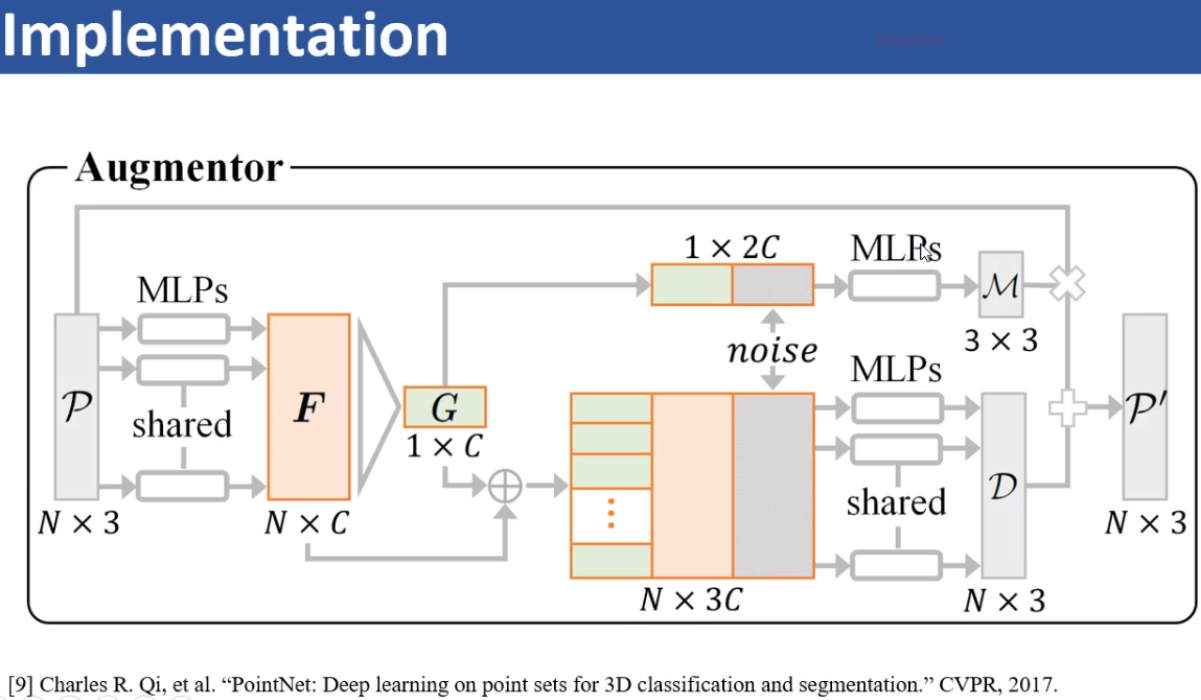
构建网络部分对于augment来说不是重点,关键在于如何训练,分类网络会告诉增强网络这个增强样本好还是不好,那么怎么定义好与不好?对于augmentor来说,没有GT,所以它更像一种自监督学习,这里给出两个requirement
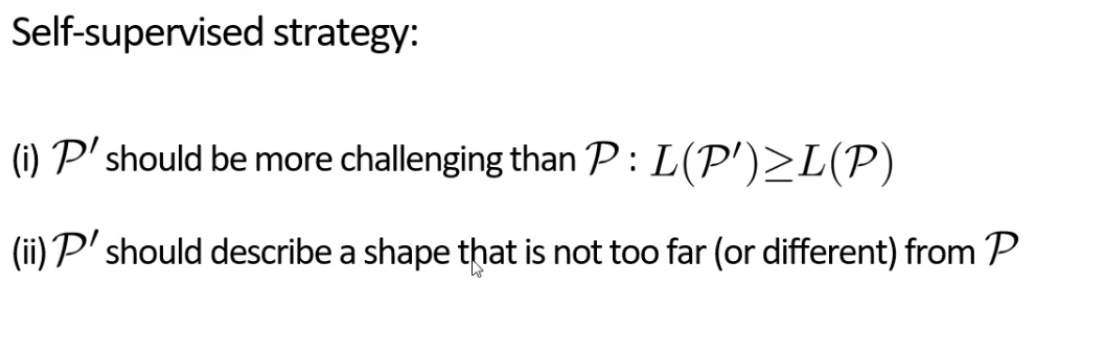
讲者提出的solution,这是一种简单的版本,没有考虑到requirement(2)

接下来引入了一个动态调整的边界参数$\rho$,去调整增强样本的复杂度,刚开始的时候比较低,随着$\rho$增大,增强样本的复杂度增加。

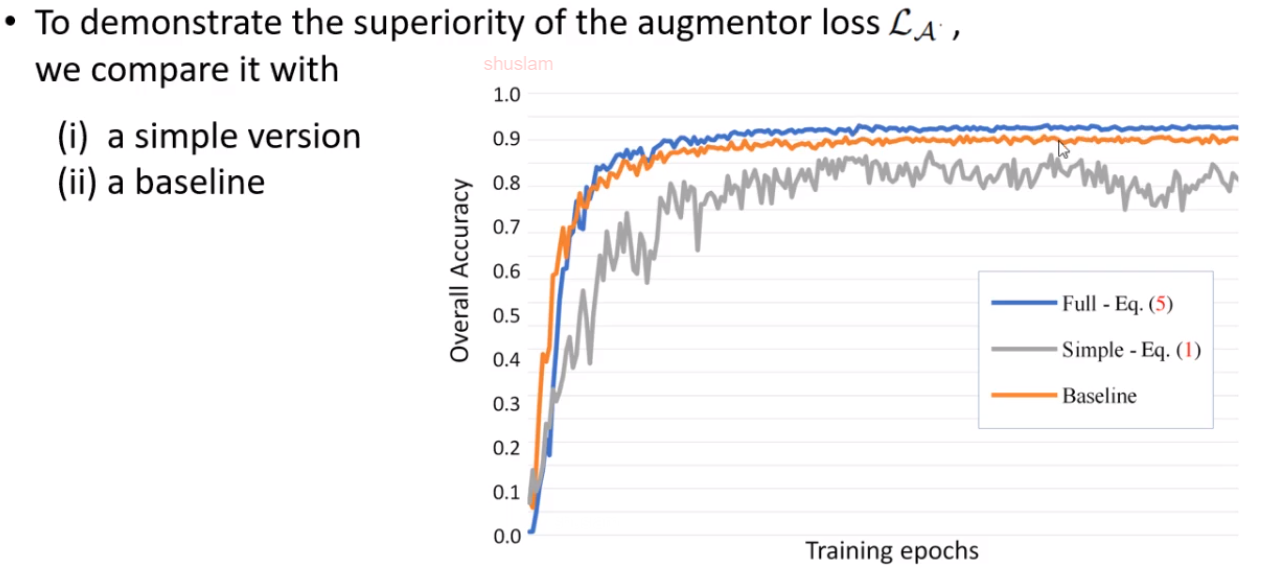
实验验证设计的loss有效性,橘色的线是用pointnet++做的baseline
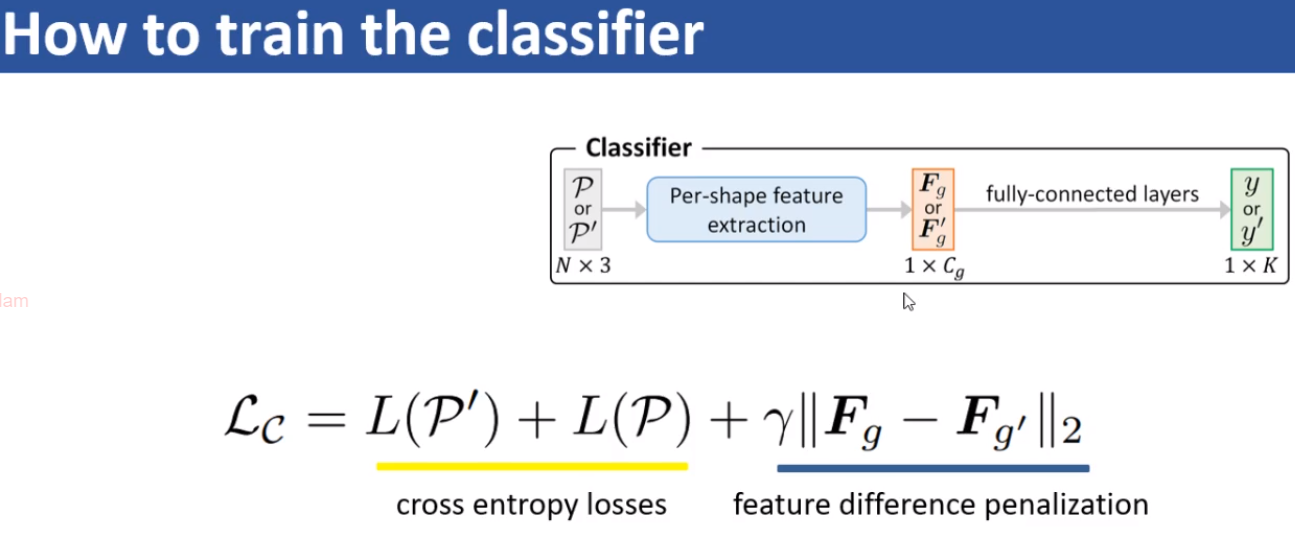
接下来是分类器的loss介绍,目的是为了让生成器和原始点云的Feature尽量接近
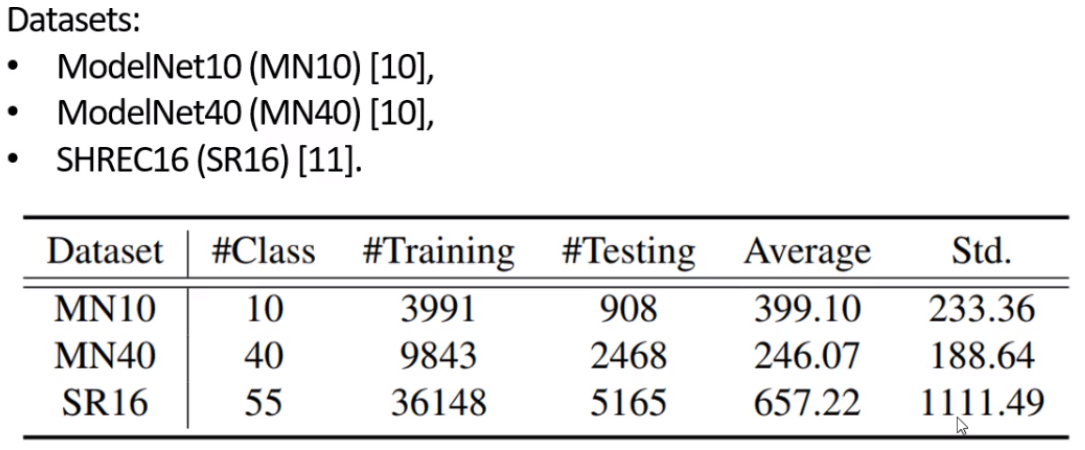
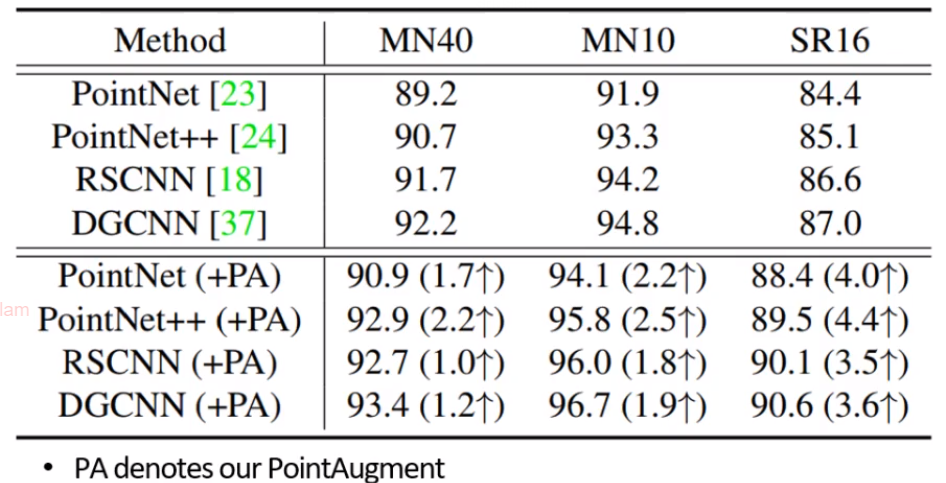
实验用到的数据集和实验效果,能够看到它在imbalance的数据集上提升更大。
鲁棒性的验证
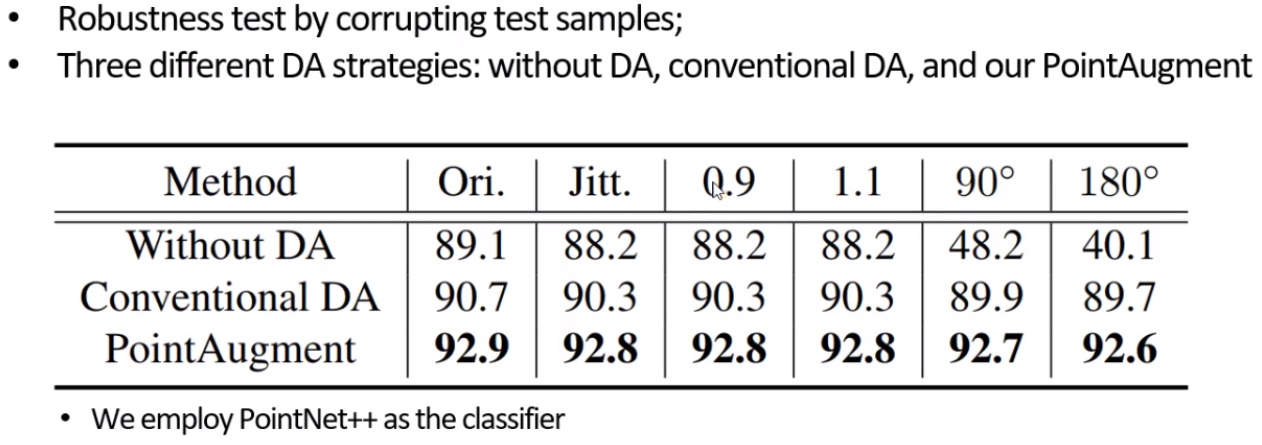
自动数据增强的工作是从谷歌的19年文章出来后才慢慢引起注意
